In financial services institutions, the ability to analyze relationships between large-scale data, uncover historical connections, and perform these operations in real time is essential for various business needs. Fraud detection systems, a prime example of such systems, are real-time decision-making mechanisms aimed at preventing financial fraud. These systems utilize various rules and/or machine learning methods, which are run simultaneously during financial transactions, enabling the monitoring of transactions and the instantaneous implementation of preventative actions. Deciding how to model the data is a critical design consideration for these systems, which are expected to be capable of low latency response in an environment processing a large volume of transaction data.
In this article, I'll share how we decided to move away from a relational database system while designing our fraud detection product, which is actively used at Kuveyt Türk Participation Bank and analyzes nearly 2.5 million transactions daily to produce decisions. I'll also share the pros and cons we encountered during this period. Along the way, we'll also touch on the advantages and disadvantages of running the RDMS system.
Database Models
There are two fundamentally different database models for storing and managing data for applications: relational and non-relational. Non-relational databases also have different variations, which we'll briefly discuss.
Relational Database Management Systems (RDMS):
Proposed by Edgar Frank Codd in the 1970s, these are systems that model data as tables composed of rows and columns. It is considered a suitable model in many systems and is still widely used today.

What advantages does RDMS offer?
-
Performing database operations more securely with ACID support
-
The data structure is easy to understand,
-
Ensuring data integrity, data standardization and consistency
-
Reducing data size and disk costs by reducing repetitive data through normalization,
-
The tools and methods have become standardized due to long-term use,
-
Reporting and queries can be made easily using query languages that most people are familiar with.
Relational database management systems have many advantages, such as those listed above.
Creating a more rigid, tabular data model with predefined rules, lengths, and types may be appropriate for many large-scale applications (such as banking systems). Such systems require standards-compliant structures that allow for controlled data architecture, are more auditable, and minimize errors.
However, this database model can be disadvantageous for applications that require a flexible data model and rapid adaptation to change. Furthermore, as data size and complexity increase, performance can suffer due to vertical scalability, which can lead to costs such as adding more processors and RAM to servers. Even if these costs are considered, hardware limitations can still arise.
Non-Relational (NoSQL) Database Systems
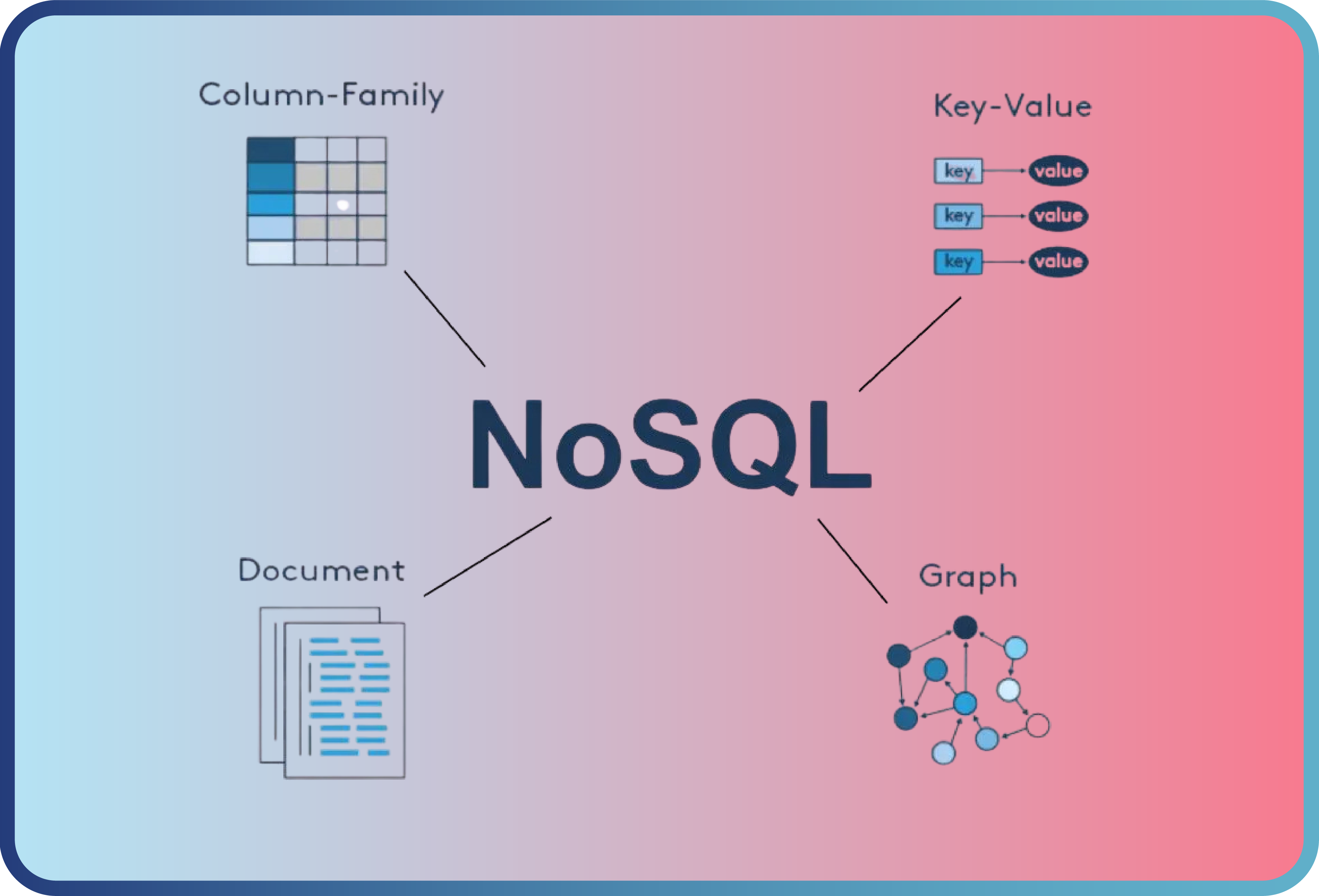
NoSQL databases are types of databases that provide flexible and scalable storage of data. Unlike traditional relational databases, NoSQL databases do not require a fixed schema and are generally optimized for working with large data sets.
Today, with the emergence of big data and related technologies, we see the popularity of NoSQL databases. Of course, there are different alternatives here as well. There are varieties such as Document-Oriented, Key-Value, Wide-Column, Graph, etc. Each one addresses different needs.

Let's briefly touch on the characteristics of these different types:
-
A document store (document-based data store) is a type of database that stores data in a document-oriented model. Each record and its associated data can be stored within a single document. These documents are typically in JSON or XML format.
-
A graph store (graph-based data store) is a type of database that stores data using nodes, edges, and properties. Nodes represent objects, and edges represent relationships between nodes. This type of database allows for rapid querying and visualization of relationships.
-
A wide column store is a type of NoSQL database that stores data in column families. Each column family represents a group of related data, and each row has a unique key.
-
A key-value store (KV) is a type of NoSQL database that stores data as key-value pairs. Each key is a unique identifier and is used to retrieve its associated value. This structure is ideal for scenarios where speed and scalability are critical. Key-value store databases typically use hash tables or similar data structures. Table 1.0 shows which database solutions fall into each category.

Table 1.0: NoSQL Database Solutions by Type
Weaknesses of the Relational Database System and the Needs of Our Application
In the system we developed, we needed to use a database that would meet the needs I have listed below.
-
Flexible Data Structure
One of our biggest challenges when we used relational database management systems was the difficulty presented by the requirement for a predetermined data structure. Detecting fraud requires creating systems capable of making decisions by combining information about when, where, and how millions of transactions of hundreds of different types occurred. Each transaction has its own unique data characteristics and is managed by its own data models. Each of these transactions can be a potential fraud case, and these transactions, with their different data structures, must be collected in a transaction pool and used as reference data for subsequent transactions.
We needed to ensure that any data could be imported into the system and used when needed, simply by making definitions.
-
Ability to Develop and Take Action Quickly
Because fraudsters are uncertain about when they will attack, immediate action is necessary, and the system must adapt quickly. In our relational model, the processes required to make the information necessary for providing new data available, create scripts, and transfer it from the database to the live environment could delay these actions. When we wanted to add new information to the system, we couldn't implement the change as quickly as we wanted because table changes, code changes, stored procedure changes, and so on, had to be processed through approval processes from the lower environment to the upper environment.
-
Centralized Data Structure
Another problem we encountered was the difficulty of creating a centralized data model with a relational data structure. Because transaction sets had different and unrelated data structures, creating separate tables for each of them prevented us from gathering data in a central location. Even if we designed a table containing all the existing data, we had to create table designs with many null fields. Going with table designs with many null fields was inefficient, and making changes to tables with continuous data flow also posed a risk. Another alternative we considered was creating a key-value data structure, but this was also ineffective. It required performing n insert operations or batch inserts containing n data at a time. Write performance is crucial in these systems, and read speeds are affected in tables with high write flow.
Failure to create a central data structure required accessing data from different points, which increased the time spent on processing and prevented responses from being provided quickly enough.
-
Ability to Meet Needs in Increasing Transaction Numbers and Transaction Diversity
Back when the number of entities/relationships/concepts to be managed in the database and the number of transactions were low, and customer expectations weren't as high, changing relational database habits perhaps wasn't as necessary as it is today. Furthermore, the critical point of abandoning some of these systems' advantages hadn't yet been reached. With the development of our banking application, BOA, and the increase in branch, channel, and product diversity, it was inevitable that the number of transactions that needed to flow through these channels to the fraud detection system would also increase. The emergence of new transaction types, such as FAST, which provides convenience to our customers and allows for instant transfers, began to change customer habits and expectations, while also creating a need for increased response times (other bank transfers made via EFT have a waiting period of up to a minute before being transferred to the receiving bank, allowing these transactions to be checked asynchronously and necessary actions to be taken before the transfer takes place). Furthermore, as the variety of transactions and the number of channels available to customers increased, this also opened up new avenues for fraudsters to develop new methods. These new fraud methods, coupled with the increasing number of transactions between them, required greater attention to the interrelationships between transaction types across channels. For example, a debit card withdrawal made by a fraudster might be linked to a different transaction type from the previous one.
-
The Need for an Isolated System
As the number of transactions increased, the background operations created a greater load on the system. To ensure traceability of decisions, the results obtained at each step were recorded in tables, and intensive write and read operations could have negative impacts on the systems. A system that was completely isolated from the servers where core banking transactions took place, yet still operated at high availability, was needed. Horizontally scalable was also crucial for meeting future needs.
Final Decision: NoSQL => MongoDB
When we evaluated all these needs, we decided to move forward with a NoSQL database. The data structure we were trying to process was like files with distinct contents, and we needed a system with high querying capabilities within these files. Therefore, we believed a document-oriented structure was more suitable for us, and considering other factors, we decided to choose MongoDB.
Factors affecting our choice:
-
Flexible document-based data structure and query capability
MongoDB uses the concept of collections instead of tables. Each document in a collection can have different content as needed, schema and data type restrictions can be adjusted as needed, and advanced queries can be run on this data structure.
-
Popularity
Having a system that's known and used in the market is always advantageous. You can get ideas from many developers who share their experience, such as db-engines.com.According to the pages measuring database popularity, the situation in document-based pages is as shown in Table 2 below. (The situation in February 2025)

Table 2: Document Based NoSQL Database Popularity Scores According to DB-Engines Ranking [3]
-
Ability to develop and experiment with the Community version
Having a free version is easy to useIt allows us to quickly download and begin experimenting. Upgrading to Enterprise doesn't require any additional effort, especially for the higher-level features offered by the database management platform. Aside from licensing costs, we can migrate directly to the same application.
-
Ease of use of C# Drivers and compatibility with our existing infrastructure
We were able to easily adapt to the use of drivers in the software development stages in the .Net environment.
-
Replicaset and Sharding support
With a redundant architecture that automatically synchronizes with each other using replicaset logic, it's possible to run tasks without interruption. Shards can be created when necessary to distribute data across different nodes. If one node is shut down while work is in progress, the application can continue to operate uninterrupted from the other nodes.

-
Support for multiple engine types (working with in-memory engines if necessary)
A node can be configured that can only hold data in memory. If your data fits in memory, you can optionally support persistence with two in-memory nodes and one wired tiger node.
-
24/7 support, OPS Manager and LDAP Support with the Enterprise version
Community edition is available, but if you're new to MongoDB and running a large-scale system, support is always important. We've had to contact support for many different issues, both on the application side and the database administration side. This support was especially crucial for us since we're working with a new database system. If you want to use LDAP as a central authentication structure, you can take advantage of this feature, which comes with the Enterprise edition. This is considered a crucial requirement for security and centralized user management in large organizations. OPS Manager simplifies the work of the database administration team.
-
Performance
MongoDB is known to have good write, read, and delete performance. There are also comparison articles on this topic, and some research indicates that MongoDB performs better, except for some combined operations. [1]
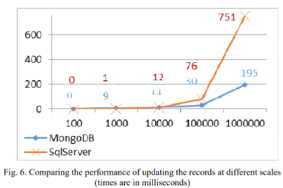

Figure 1.0: MongoDB write performance comparison [1]
-
Temporal Index Management
Being able to control data size by automatically deleting unneeded data after a certain period of time with TTL Indexes is an important feature for our application.
-
Compliance with Agile Software Development Processes
It enables rapid software development. With the code-first approach, we can produce much faster than the old system.
-
Functions Automatically Managed by Drivers
In case of any server shutdown or maintenance, the driver automatically switches to the primary nodes, allowing us to carry out operations on the nodes without interruption.
Subjects We Have Difficulty With
We can summarize the difficulties we experienced in this process as follows:
-
Breaking the Relational Design Habit
Relational database habits shape how we think during system design. While we generally use NoSQL because we're accustomed to thinking in relational terms, if we don't design the application accordingly, we may not achieve the expected benefits.
MongoDB recommends normalizing data that is directly related and accessed together and keeping it in the same document rather than spreading it across different tables. This, it claims, ensures atomicity. It's important to break free from design habits like spreading information across two different tables, linking them with foreign keys, and accessing them through joins.
Of course, there is a maximum size limit for each document, which is 16 MB.
-
Getting Familiar with the MongoDB Query Language
One of the most challenging aspects for us initially was that when we tried to write complex queries, it wasn't as easy as it is in SQL. I still can't say we're fully accustomed to it. It has a very flexible query structure, but when writing a query, it requires getting used to writing in JSON format.

Some tools help with writing SQL and converting it to MongoDB Query, but these tools aren't available everywhere. We should also mention the NoSQLBooster tool here. It made our work much easier, both during and after the initial setup phase. It offers more advanced features than MongoDB Compass.
-
MongoDB Compass Needs Improvements
I believe MongoDB has room for improvement. Compass is available for free, but it doesn't offer much in the way of database management. Alternative applications offer many more features. We decided to stick with NoSQLBooster, which we believe is a much more useful tool. However, perhaps because we've become accustomed to it and have been using it for years, I can't say that any of it is better than SQL Server Management Studio.
-
Database Management and Process Establishment
Simply deciding to use a database isn't enough; experience also takes time. Getting used to managing the tools required for installation, database configuration, maintenance, and backup operations, access configuration, and even some operating system configurations can impact performance. We received consulting services from MongoDB on these issues, but it takes time to build knowledge and for both software and database management teams to adapt to the new system's behavior and gain experience.
-
The Need to Merge Data with Data from a Different System
Writing data to collections is easy, but if you need to read it, combine it with data in a relational system, and generate a report, difficulties arise. This can be solved using data export tools, but a solution like in relational systems, such as writing an SP to the X DB, executing it, importing it into tempdb, and joining it, etc., isn't possible.
In the final case, I can summarize the advantages we achieved such as a more optimized system in terms of performance and number of database operations, an improvement of nearly 50% in response times, flexible and easy-to-manage interfaces, a centralized data model and faster code development.
This was our experience with the transition to a NoSQL Document Based system in terms of application development.
See you in different articles.
References:
[5]Non-Relational Databases and Their Types - GeeksforGeeks
“This content is intended solely to provide a high-level overview of our architectural principles. Operational processes, rule sets, configurations, and implementation details related to banking security are outside the scope of this publication.”