In recent times, artificial intelligence has moved beyond being a field focused solely on model development, transforming into a set of systems integrated into real-world processes. In the past, the fundamentals of deep learning models, CNN–RNN architectures, optimization algorithms, data processing techniques, and classical machine learning approaches were at the forefront for an AI engineer. These topics still retain their importance today; however, the main focus has now shifted elsewhere.
Today’s AI ecosystem is shaped more by the question “how do we turn this model into a working system?” rather than “how do we train the model?”. In other words, the issue is not just to produce a smart model; it is to transform this model into structures that can make decisions, generate actions, and be integrated into processes.
From this point on, it is necessary to combine theoretical knowledge with practical system design. The concept of agents and agent orchestration emerge exactly as a result of this need.
What Does It Mean to Manage Artificial Intelligence?
In recent years, “prompt engineering,” which we hear about frequently, has come to the forefront as one of the first steps in guiding artificial intelligence systems. Basically, this approach aims to use the knowledge the model possesses more effectively by asking the right questions to the AI.
However, over time, an important problem has emerged: To effectively guide artificial intelligence, it is necessary to have a certain level of command over the area being directed. Otherwise, the user may inadvertently misguide the model, and the results produced may lose their reliability. This situation clearly demonstrates that approaches based solely on asking questions are limited.
Transition from Prompt Engineering to Context Engineering
In recent years, it has become clear that the “prompt engineering” approach, which is based on guiding artificial intelligence systems through one-off prompts, does not fully meet the needs of the sector. Therefore, the concept of “context engineering,” which offers a more comprehensive and sustainable framework, has started to come to the fore. Context engineering aims to define in detail the environment in which artificial intelligence applications will operate, for what purpose, and within what boundaries. In this way, systems are no longer just structures that respond to instant prompts; instead, they operate within a holistic framework.
Building the right context paves the way for artificial intelligence systems to work in a predictable, controllable, and reliable manner. With this approach, artificial intelligence becomes not only a tool that generates answers, but also a digital assistant serving a specific corporate goal. Thus, when artificial intelligence technologies are integrated into business processes, reliable and effective solutions tailored to the expectations of institutions can be provided.
Within this framework, the importance of the context engineering approach is also increasing in LangChain-based software processes. In the next section, how the software components developed within this scope can be orchestrated holistically will be discussed.
What Is an Agent and Why Does It Exist?
Artificial intelligence began to slowly emerge from a long period of stagnation with the large language model published by ChatGPT in 2022. Here, it is important not to overlook the main concept: Artificial intelligence today is not limited to the large language models everyone is talking about. To better understand the topic, I am sharing a diagram below for you to review.



Where were we? Thanks to ChatGPT, a wide window of opportunity opened before us. Afterwards, many artificial intelligence companies tried to solidify their position in the sector by taking advantage of this opportunity. Essentially, this process paved the way for the development of large language model (LLM) technologies and the emergence of new ventures and projects based on these models.
As usage areas expanded, the system's shortcomings also became increasingly apparent. LLM models were limited to producing only one output for a given input; in other words, receiving a text output from a text input was no longer sufficient. Many problems arose here: lack of access to up-to-date data, outputs being offered only in text format (making it impossible to take action), and the reliability of the responses obtained were just some of the limitations.
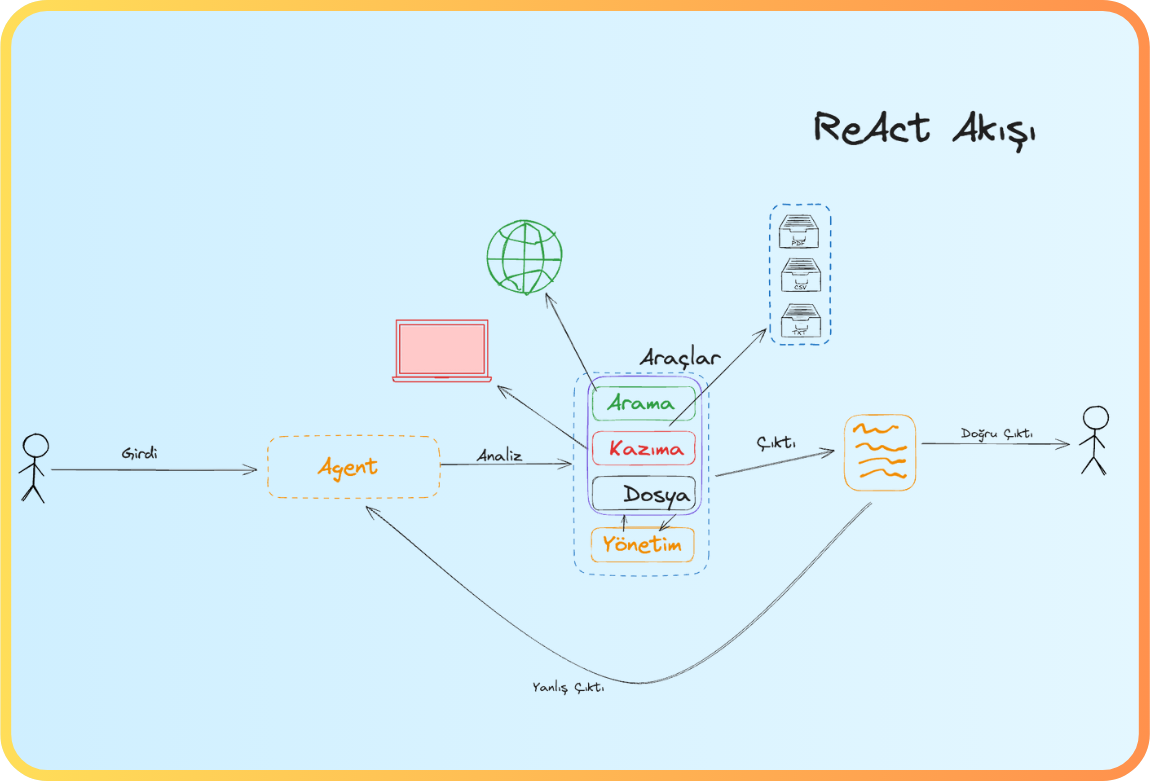
At this point, software components that can independently make decisions and take action come into play—namely, agents. This was exactly the main function that LLMs alone could not fulfill: they merely analyzed data but could not intervene in the outside world. Agent architecture gives LLMs a physical presence, turning them into autonomous systems that can perceive their environment, set goals, create plans, and take action to execute those plans. Now, LLMs can perform web searches when needed, make API calls to carry out operations in a system, and initiate their own loops to deepen research; in short, they acquire an intelligence that could be described as “search, apply, bring.” Thus, they move from being passive chatbots to becoming active digital workers that carry out tasks.
In more technical terms, an Agent is an autonomous software module that processes inputs from its environment (such as sensor data, user requests, system outputs, or web-based information), analyzes this data with a specific goal in mind, and then selects and implements the appropriate actions. Here, the LLM forms only the “cognitive” layer of this structure; agent architecture builds on this foundation by adding memory, tools (functional modules), a planning unit, an execution layer, and a feedback mechanism, thus creating a holistic system that can act autonomously, make decisions, and complete tasks on its own.
Agents Stronger Together

In theory, there doesn’t seem to be a problem; the agent takes over tasks, relieves our workload, and automates processes on our behalf. However, when it comes to implementation, an important reality emerges: a single agent is often not enough. This is because complex business problems typically require coordination across several areas of expertise, different toolsets, and independent sub-tasks. Trying to handle all these tasks with just one agent slows down the system and increases the error rate. Instead, just like in a real team, several agents need to work together, orchestrating tasks handed off from one to another. For example, there could be an agent that conducts research, another agent that processes the results of this research, and a separate agent that evaluates the output obtained.
In the next section, we’ll proceed with more technical details and code examples. During this process, we’ll use the Langchain platform. If you’re curious about what Langchain is, you can check out the details at the link below.
LangChain Documentation: https://docs.langchain.com/
To summarize briefly, Langchain is a technology company focused on agent development that offers different software frameworks for this purpose. There are open-source frameworks such as Deepagent, Langchain, and LangGraph. Now let’s move on to the agent architecture:

Basic Components of the Agent
When you want to design an agent, you basically encounter two main elements. The first is the “Tool” that gives functionality to the agent, and the second is the agent itself, in other words, the “Agent”.
Tool: These are function-based software modules that enable agents to gain the ability to process and act.
Agent: Represents the agent itself. By using tools, it produces outputs according to the inputs provided by the user and processes these outputs in line with the system’s objectives.
Defining Tools in Langchain
To define a tool in Langchain, you must first install the relevant packages. Here, I will use the Python SDK; if you wish, you can also choose the TypeScript SDK.
pip install -U langchain
After installing the main required package, you can create a file named main.py to write your main code:

We define the function we created with the Tool decorator as a tool for the agent. The description lines within the tool are very important; because the large language model (LLM) within the agent decides whether to use this tool or not by looking at these descriptions. Now, let's develop a few more different tools.

Let’s have another tool as a division user registration tool; my aim here is to show that you can customize tools according to your needs in different areas. While our first tool performs a web search, the second one could save files, and maybe the third one will do data analysis—the important thing is to understand this basic logic.
I’d like to share some technical tips I’ve gained while developing a tool: The definition of a tool is essentially a function, and you should design it with the awareness that every operation in this function can result in an error. As in software development, you must approach “Error Handling” with care when defining tools. Otherwise, if the agent cannot get the expected result after calling the tool, it will keep retrying, exploring faulty paths, and this will increase the model’s operating cost. Therefore, error handling is quite important. Another critical point is that the purpose and scope of the tools you develop must be clearly defined; having a tool perform multiple tasks is against software architecture principles. Each tool should fully accomplish its own function and work independently. This way, the agent can predict the output format when using the tool and produce a suitable response.
From Tools to Agents
Now we have various functional modules (tools) at hand; next, let’s move on to defining the Agent that will use these modules. As the first step, the required model structure needs to be created.
During the model creation phase, you can choose any service provider offered by Langchain. In this example, I will use the Gemini model.

The model definition can be made in a very straightforward way; here, it is possible to configure which service provider will use which model, the accuracy and clarity level of the output produced by the model, as well as various parameters such as
max_tokens and timeout.
Agent basically aims to provide functionality to the Large Language Model (LLM). Therefore, the features of the model you choose according to the purpose and scope of your existing tools are also critically important. We will revisit this topic in the following sections.

To create an agent, we will use the create_agent function and define some parameters. First of all, we need the tools that we determined earlier and the LLM model (Large Language Model) that will use these tools. Then, the following critical parameters come into play:
One of the most important parameters you can specify when creating an agent is the system_prompt. This prompt defines the agent’s overall attitude, role, and target behavior. If a solid direction is not provided, the agent acts entirely dependent on the model and inconsistent results may emerge.
Then comes the middleware structure. Middlewares work almost like an agent’s “traffic controller”; they can change behaviors before or after the model call, direct tool calls, add logging, or provide custom situation management.
Another important parameter is the response_format. Here, you can request the agent to produce a structured output. For example, JSON format, a custom Pydantic model, or more advanced automatic/strategy-based directions. When this parameter is given, the agent tries to adapt the response from the model to this format.
Then comes the state_schema and context_schema. These are critically important in scalable systems because they allow you to customize the state the agent maintains during its operation. Combined with middlewares, you implement the principle of “each agent knows its own state” in multi-agent structures.
The interrupt_before and interrupt_after parameters are used to have the agent stop at certain points, get approval from the user, or trigger a special action. For example, before a tool call that will perform a “delete” operation, you can stop and ask the user “are you sure?”
When all these parameters come together, the create_agent function creates a fully functional agent graph according to the configurations. The model generates messages; based on these messages, it calls the tools, sends the tool results back to the model, and this cycle continues until the tool call is completed.
If you have made it this far, you now know the agent concept and can feed it with tools. Depending on your needs, you may need to create dozens of agents and dozens of tools. The simplest example of this emerged in a project I worked on recently. I’m leaving it below: with dozens of tools and the agents that manage these tools, and a supervisor agent that manages them. Yes, you read it right; there is also an agent that manages agents (supervisor agent).


We had equipped this agent with various capabilities using different tools; however, there are still some missing elements. What could be lacking?
In daily work life, the goal in a project is to reach a common output with people who have different areas of expertise and different main focuses. For example, while developing a web platform, one team member may specialize in frontend, another in backend, and another in devops. As you can see, people with different knowledge and skills come together and collaborate to achieve a common goal.
Returning to the agent architecture again; if we have only a single agent, for example, it can only handle frontend development tasks or only perform backend functions. However, if multiple specialized agents are defined, it becomes possible to achieve the desired project output in its entirety. With agents possessing multiple areas of expertise, it is possible to produce a more professional and comprehensive result. But...
A multi-agent structure means multiple responsibilities. Agents specialized in a single area need to communicate, be managed, and be directed so that the final output can be obtained as expected. If you think this background information is sufficient, we can now move on to the Multi-Agent Structure.

What is a Multi-Agent Structure?
It is a systematic structure that enables multiple agents to collaborate and achieve a common goal. At its core lies the idea of bringing together different and specialized agents to attain a holistic solution. Such a structure aims to produce more comprehensive and efficient results by coordinating agents specialized in their respective fields.
To set up this kind of structure on the Langchain platform, first, the relevant libraries must be installed completely.
pip install -U langchain
After installing the required package, we can start creating the basic components needed. As I mentioned before, if we are to design a multi-agent architecture in a software development process, we need to go beyond atomic structures. Therefore, it is important to first define the tools that will be used.
To avoid problems in the future and to establish a sustainable multi-agent architecture, you can find below the file structure I generally prefer.

When we look at the Tools folder, it would be a more appropriate and corporate approach to create a directory structured as below, considering multiple tool definitions for each agent.

Let’s take a closer look at some of these tools. For example, what does the API tool mean for us, what capabilities does it have?

An example tool included within automatically designs RESTful API endpoints.
Let's move on to another tool; let’s examine the suggest_layout_improvement tool, which is among the design tools used by the Frontend agent.

This tool analyzes the layout of pages and components (customized for React-based applications), providing users with suggestions for improvement.
Now, we can understand the basic functions and boundaries of the tools more clearly. Next, let's take a look at the agent structures that will give functionality to these tools and actively utilize them.
When we take a closer look at the backend agent, we see that we have created our agent with the fundamental components discussed in the previous article. These components consist of the tools the agent will use in its operations, along with the Large Language Model (LLM) configuration that enables the effective use of these tools.

If we have grasped the Tool and LLM (Large Language Model) architecture, I would like to highlight another critical point here. Agents are not structures that comprehend their functions solely through tools; at this point, they are still open to development. For the agent’s tasks and areas of authority to become clear, a guiding and role-defining structure is required. This is where the system_prompt comes into play. The system_prompt is a command sequence that clearly defines the role, scope, and boundaries the agent will assume. For example, with a script like the one below, you can establish the agent’s job description and responsibilities in a corporate manner:

With this system_prompt, it is clearly defined which tasks the LLM can perform and which it cannot. Additionally, if you wish, you can create a sample chat history in this section to provide further guidance to the model. These are important details to pay attention to during implementation and can be revisited if requested in the future. Now, let’s continue with the process.

After transferring the relevant tools, Large Language Model (LLM) configuration, and system guidance commands, we set up our backend agent. You can develop other agents using the same principle. Now, let's move on to DeepAgent.
Let's Define the Supervisor Agent
The supervisor agent acts as a higher-level agent that manages the agents we have created so far. In corporate business life, you can think of this agent as a product manager; a responsible structure that assigns tasks to each participant and tracks the outputs. When developing the supervisor agent, we will not follow a method different from the standard agent definition process. The main difference here is that our tools will actually consist of agents.
An example Frontend tool definition for the supervisor agent is given below:

The point to pay attention to in this definition is that the tool, in the background, performs an agent call (agent call) and returns the response it receives from the relevant agent. Now, let’s take a closer look at the backend tool definition.

Now, let's examine the version of the guidance prompt (prompt) used in the high-level supervisor configuration that calls these tools, translated into Turkish with technical and corporate terminology:

There is a critical point to consider here: If the supervisor agent is not guided in a sufficiently clear and systematic manner, the other agents cannot carry out business processes efficiently. For this reason, as you can see in the attached file (you can review the relevant screenshot), the system command (system_prompt) consists of a detailed and comprehensive definition of approximately 150 lines. The supervisor agent must know exactly who is assigned which tasks, the logic of the system’s operation, and the steps to be followed.
Thus, in the end, we have addressed how the tool → agent → high-level agent (superagent) configurations should be set up with a holistic approach.
If you would like to get more technical details and comprehensive information, you can reach out by sending me a message. I would be happy to answer your questions.