Yapay zekâ (AI) hakkında yeni olan veya bazı kavramları duyup bunların nasıl kullanıldığını tam anlamayan herkes için bu blog yazısı rehber niteliğindedir. Yapay zekâ kavramlarını temel seviyede açıklayacak hem de büyük dil modeli (LLM) adı verilen güçlü bir yapay zekâ teknolojisine de giriş yapacağız. Başlangıç olarak temel kavramlarla başlayalım.

Şekil 1. Yapay zekâ katmanları
Yapay Zekâ (Artificial Intelligence- AI)
Yapay zekâ, bilgisayar sistemlerinin insan benzeri zekâ gösterme yeteneğini tanımlayan genel bir terimdir. AI, büyük veri setleri, güçlü hesaplama kaynakları ve ileri algoritmalar kullanarak karmaşık problemleri çözebilir. AI'ı iki ana kategoriye ayırabiliriz:
● Dar Yapay Zekâ (Narrow AI): Belirli bir görevi yerine getirmek üzere tasarlanmış sistemleri ifade eder. Örneğin, Siri veya Alexa gibi sesli asistanlar, yüz tanıma sistemleri ve öneri motorları dar AI uygulamalarıdır. Bu sistemler yalnızca belirli görevler için optimize edilmiştir ve farklı bir alanda kullanılamaz.
● Genel Yapay Zekâ (General AI): İnsan zekâsına eşdeğer bir genel zekâ seviyesine ulaşmış yapay zekâdır. Bu tür bir yapay zekâ, tıpkı insanlar gibi çok çeşitli görevleri yerine getirme yeteneğine sahip olacaktır. Ancak, bu düzeyde bir yapay zekâ henüz geliştirilememiştir ve araştırma aşamasındadır.
Makine Öğrenimi (Machine Learning- ML)
Makine öğrenimi, bilgisayar sistemlerinin veri kullanarak öğrenmesini sağlayan bir yapay zekâ dalıdır. Yani, bir sisteme sağlanan büyük veri kümeleri sayesinde, algoritmalar belirli desenleri öğrenir ve bu öğrendikleriyle gelecekte daha doğru tahminler yapabilirler. Makine öğrenimi, yapay zekânın temel yapı taşlarından biridir ve çeşitli alanlarda kullanılır.
Makine Öğrenimi Nasıl Çalışır?
Makine öğrenimi, algoritmaların verilerden örüntü ve ilişkiler öğrenmesi ile çalışır. Bu algoritmalar, veriler üzerinde eğitim aldıktan sonra, yeni verilere dayalı tahminler yapabilir. Ana amacı, verilerdeki özellikleri analiz ederek, girdiler ve çıktılar arasında bir ilişki kurmaktır. Bu süreç genellikle şu adımlardan oluşur:
- Veri Toplama: Modelin eğitilmesi için ihtiyaç duyulan veriler toplanır.
- Veri Ön İşleme: Toplanan veriler temizlenir, eksik veya hatalı veriler düzeltilir ve veriler model için uygun formata dönüştürülür.
- Model Seçimi: İlgili problem için en uygun makine öğrenme algoritması seçilir.
- Model Eğitimi: Model, veri seti üzerindeki örüntüleri öğrenmeye başlar. Bu aşamada modelin performansı çeşitli metriklerle ölçülür.
- Model Değerlendirme: Modelin doğruluğu ve genelleme yeteneği test verileri ile değerlendirilir.
- Tahmin ve Karar Verme: Model eğitildikten sonra yeni verilere dayalı tahminler ve kararlar verebilir.
Makine Öğrenimi Türleri:
Makine öğrenimi, temel olarak üç ana kategoriye ayrılır:
- Denetimli Öğrenme (Supervised Learning): Denetimli öğrenmede, modelin eğitim verileri hem girdi (input) hem de karşılık gelen doğru çıktılarla (output) etiketlenmiştir. Model, girdiler ile çıktılar arasındaki ilişkiyi öğrenir. Modelin amacı yeni verilere dayalı doğru çıktılar tahmin etmeyi öğrenir. Örnek olarak ev fiyatlarının, evin özelliklerine (büyüklük, konum, oda sayısı) göre tahmin edilmesi verilebilir.
- Denetimsiz Öğrenme (Unsupervised Learning): Denetimsiz öğrenmede, modelin eğitildiği verilerde etiket yoktur. Model, yalnızca girdilerden anlamlı örüntüler ve ilişkiler bulmaya çalışır. Modelin amacı verilerin yapısını keşfeder ve verileri gruplandırır ya da sıkça tekrar eden örüntüleri bulur. Örnek olarak web sayfalarında veya ürünlerde benzer içerikleri bir araya getirmesi verilebilir.
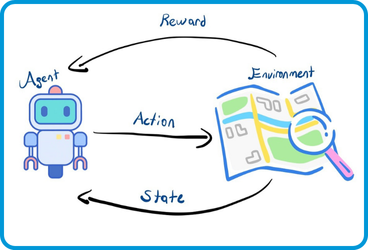
- Pekiştirmeli Öğrenme (Reinforcement Learning): Pekiştirmeli öğrenmede, bir model, bir ortamda kararlar alır ve aldığı kararlar sonucunda bir ödül ya da ceza alır. Amaç, zamanla doğru stratejileri öğrenmektir. Modelin amacı en yüksek ödülü almak için hangi adımların atılması gerektiğini öğrenir. Örnek olarak satranç oynayan bir yapay zekanın, doğru hamleleri öğrenmesi verilebilir.
Makine Öğrenimi Algoritmaları:
Makine öğreniminde kullanılan birçok farklı algoritma vardır. İşte en popüler olanlar:
- Lineer Regresyon: Sürekli değişkenleri tahmin etmek için kullanılır. Girdiler ve çıktı arasındaki doğrusal ilişkiyi öğrenir.
- Lojistik Regresyon: İkili sınıflandırma problemlerinde (evet/hayır) kullanılır.
- Karar Ağaçları: Girdiler ve çıktı arasındaki ilişkileri hiyerarşik olarak öğrenir. Veriyi, çeşitli kurallara dayalı olarak dallara ayrılır.
- Destek Vektör Makineleri (SVM): Veriler arasındaki sınırlayıcı çizgiyi bulmaya çalışır ve sınıflandırma problemlerinde kullanılır.
- K-En Yakın Komşu (K-Nearest Neighbors - KNN): Yeni gelen veriyi en yakın komşularına bakarak sınıflandırır veya tahmin eder.
- Kümeleme (Clustering): Verileri önceden belirlenmemiş gruplara ayırır.
- Rastgele Ormanlar (Random Forest): Birden fazla karar ağacını kullanarak daha doğru tahminler yapar.
Makine öğrenimi, büyük verilerden anlamlı bilgiler çıkarmak ve insan müdahalesi olmadan kararlar almak için güçlü bir araçtır. Birçok uygulamada, insanlar yerine otomatik olarak kararlar alabilir ve tahminler yapabilir. Model, yeni veri aldıkça kendini geliştirebilir ve daha iyi sonuçlar verebilir. . Fakat bununla birlikte derin öğrenme bazı zorlukları da beraberinde getiriyor. Bunlar;
● Veri İhtiyacı: Etkili makine öğrenimi modelleri oluşturmak için büyük ve kaliteli veri setlerine ihtiyaç vardır.
● Aşırı Uydurma (Overfitting): Model, eğitildiği verilere çok fazla uyum sağlayarak, yeni verilerde düşük performans gösterebilir.
● Algoritma Seçimi ve Ayarları: Doğru algoritmanın seçilmesi ve bu algoritmanın parametrelerinin doğru bir şekilde ayarlanması zaman alıcı ve zor olabilir.
Derin Öğrenme (Deep Learning- DL)
Derin öğrenme, makine öğreniminin bir alt dalıdır ve özellikle karmaşık veri yapılarını anlamak için tasarlanmış yapay sinir ağları kullanır. Derin öğrenme, büyük miktarda veriyi işler ve bu verilerdeki desenleri çıkarmak, sınıflandırmalar yapmak veya tahminlerde bulunmak için kullanılır. Derin öğrenme, genellikle çok katmanlı sinir ağları ile gerçekleştirilir ve büyük miktarda veri ile yeterli hesaplama gücüne sahip olduğunda oldukça başarılıdır.
Derin Öğrenmenin temeli, yapay sinir ağları (artificial neural networks) üzerine kuruludur. Yapay sinir ağları, katmanlardan oluşur ve her katman, bir öncekinden gelen girdi ile işler ve bir sonraki katmana iletir. Bu yapılar, insanların biyolojik sinir ağlarına benzetildiği için bu ismi almıştır.
- Yapay Sinir Ağları (Neural Networks): Yapay sinir ağları, üç ana katmandan oluşur:
- Girdi Katmanı (Input Layer): Modelin aldığı veriler bu katmana girer. Her bir düğüm (node), bir özellik ya da veri noktasını temsil eder.
- Gizli Katmanlar (Hidden Layers): Girdi katmanından gelen veriyi işler. Bu katmanlarda, nöronlar birbirleriyle bağlantılıdır ve her bağlantı bir ağırlık değerine sahiptir. Gizli katmanlar, verilerdeki ilişkileri ve kalıpları öğrenir.
- Çıktı Katmanı (Output Layer): Sonuç üreten katmandır. Model, tahmin ettiği ya da öğrendiği değerleri bu katman aracılığıyla verir.
Derin öğrenmede bu katmanların sayısı fazladır. Bu yüzden bu modellere "derin" denir. Geleneksel sinir ağlarına kıyasla, derin öğrenme ağlarında çok sayıda gizli katman bulunur ve bu sayede daha karmaşık problemler çözülebilir.
- Nöronlar (Nodes) ve Aktivasyon Fonksiyonları: Her bir nöron, bir girdiyi alır, belirli bir ağırlık ile çarpar ve ardından bir aktivasyon fonksiyonu uygular. Aktivasyon fonksiyonları, çıktıyı sınırlandırmak ve modeli doğrusal olmayan hale getirmek için kullanılır.
- Eğitim ve Öğrenme Süreci: Derin öğrenme modelleri, verileri işleyerek içindeki ilişkileri öğrenir. Bu süreçte;
- İleri Besleme (Feedforward): Veriler giriş katmanından çıkış katmanına kadar katmanlar boyunca ileri beslenir.
- Geri Yayılım (Backpropagation): Modelin yaptığı hatalar (yanlış tahminler), geri yayılım algoritması ile hesaplanır ve hatayı azaltmak için ağırlıklar güncellenir. Hedef, hatayı minimuma indirmek için her adımda ağın kendini optimize etmesidir.
- Kayıp Fonksiyonu (Loss Function): Modelin tahminleri ile gerçek sonuçlar arasındaki farkı ölçen fonksiyondur. Bir nevi tahmin ve gerçek arasındaki farkı belirtir. Derin öğrenme modelleri, bu farkı minimize etmek için ağırlıkları sürekli olarak günceller.
Derin Öğrenmenin Avantajları
- Otomatik Özellik Öğrenimi: Geleneksel makine öğrenmesi yöntemlerinde genellikle el ile özellik mühendisliği yapılması gerekirken, derin öğrenme modelleri bu özellikleri kendisi öğrenir. Bu, modelin veriden daha fazla bilgi çıkarmasını sağlar. Tabii bunun sonucu olarak makine öğrenimine kıyasla çok fazla işlem gücü (GPU) gerektirir.
- Büyük Veri Setleri ile Çalışabilme: Makine öğrenme algoritmalarınının aksine derin öğrenme algoritmaları, büyük miktarda veri ile daha iyi performans gösterir. Büyük veri setleri sayesinde daha doğru sonuçlar elde edebilirler.
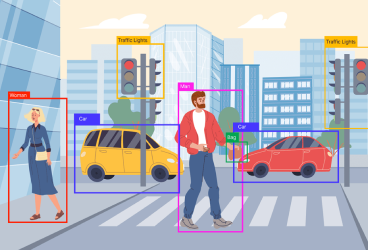
- Karmaşık Problemleri Çözebilme: Görüntü tanıma, doğal dil işleme, ses tanıma gibi karmaşık ve çok boyutlu problemleri çözmede oldukça başarılıdır.
Derin Öğrenmenin Uygulama Alanları
Derin öğrenme; Görüntü Tanıma (Image Recognition), Ses Tanıma (Speech Recognition), Doğal Dil İşleme (Natural Language Processing-NLP) gibi birçok farklı alanda kullanılır ve hayatımıza çeşitli şekillerde etki eder:
Derin Öğrenme Algoritmaları
Derin öğrenme, çeşitli mimarilere dayalı birçok farklı algoritmayı içerir:
- Yapay Sinir Ağları (Artificial Neural Networks - ANN): En temel sinir ağı yapısıdır. Genellikle giriş, gizli ve çıkış katmanlarından oluşur.
- Evrişimli Sinir Ağları (Convolutional Neural Networks - CNN): Özellikle görüntü ve video verileri üzerinde çalışmak için kullanılır. Görüntü tanıma ve sınıflandırma görevlerinde oldukça etkilidir.
- Tekrarlayan Sinir Ağları (Recurrent Neural Networks - RNN): Zaman serisi verileri ve ardışık verilerle çalışmak için kullanılır. Doğal dil işleme ve ses tanıma gibi uygulamalarda etkilidir.
- Generative Adversarial Networks (GAN): Yeni veri üretmek için kullanılan iki sinir ağı (üretici ve ayırt edici) arasındaki rekabeti kullanır. Örneğin, yeni görseller veya videolar oluşturmak için kullanılır.
- Transformer Modelleri: NLP görevlerinde oldukça popülerdir. GPT, BERT gibi modeller bu mimariye dayanır.
Derin öğrenme, günümüzün en güçlü yapay zeka teknolojilerinden biri olarak kabul edilir. Görüntü, ses, dil ve daha birçok alanda devrim niteliğinde başarılar elde etmiş olup, ilerleyen yıllarda daha fazla gelişme göstermesi beklenmektedir. Fakat bununla birlikte derin öğrenme bazı zorlukları da beraberinde getiriyor.
Bunlar;
● Büyük Veri ve Hesaplama Gücü İhtiyacı: Derin öğrenme algoritmaları, büyük miktarda veri ve yüksek hesaplama gücü gerektirir.
● Aşırı Uydurma (Overfitting): Model, eğitim verisine aşırı uyum sağlayabilir ve bu durum test verilerinde düşük performansa yol açabilir.
● Yorumlanabilirlik: Derin öğrenme modelleri genellikle "kara kutu" olarak adlandırılır; yani neden belirli bir sonucu verdiği kolayca açıklanamaz.
Şimdi de derin öğrenmenin çok başarılı kullanıldığı alanlardan Doğal Dil İşleme (NLP) yapay zekâ dalına detaylı bakalım.
Doğal Dil İşleme (Natural Language Processing- NLP)
Doğal dil işleme (NLP), bilgisayarların insan dilini anlaması, yorumlaması ve üretmesi ile ilgilenen bir yapay zekâ dalıdır. NLP, metin verilerini analiz etmek, anlamak ve doğal bir dilde yanıt üretmek için derin öğrenme tekniklerini kullanır. NLP, yapay zeka (AI) ve dilbilim arasındaki kesişimde yer alır ve makinelerin metin ve konuşma biçimindeki dili analiz etmesine, anlamasına ve üretimine olanak tanır.
Doğal Dil İşlemenin Ana Bileşenleri
NLP, dilin hem biçimsel hem de anlam bilimsel yapısını analiz eder. Bu işlem birkaç aşamadan geçer:
- Sözdizimi Analizi (Syntax Analysis): Cümledeki kelimelerin dil bilgisi kurallarına uygun olup olmadığını kontrol eder. Sözcük türlerini (isim, fiil, sıfat vb.) ve cümle yapılarını (özne, yüklem, nesne gibi) analiz eder.
- Anlamsal Analiz (Semantic Analysis): Kelimeler ve cümlelerin anlamını çözümler ve cümlenin anlamını çıkarmaya çalışır. Örnek olarak "Kitap okuyor" cümlesinde, kişinin bir materyali okuma eylemi yaptığı çıkarımı yapılır.
- Morfolojik Analiz (Morphological Analysis): Kelimelerin köklerini, eklerini ve türevlerini analiz eder. Örnek olarak "Çocuklar" kelimesinde, "çocuk" kök ve "-lar" çokluk eki olarak analiz edilir.
- Duygu Analizi (Sentiment Analysis): Bir metnin ya da cümlenin olumlu, olumsuz ya da tarafsız olup olmadığını belirlemek. Örnek olarak "Bu yemek harikaydı!" cümlesinde olumlu bir duygu tespit edilebilir.
- Bağlam Analizi (Context Analysis): Bir metnin ya da cümlenin anlamını, bağlamına göre doğru şekilde çözümler. Örnek olarak "Yüz" kelimesinin, cümlede bir sayı mı, yüzmek fiili mi yoksa insan yüzü mü olduğunu belirler.
- Adlandırılmış Varlık Tanıma (Named Entity Recognition - NER): Metin içindeki kişi, yer, organizasyon gibi özel isimlerin tanımlar. Örnek olarak "Ali İstanbul'a gitti" cümlesinde, Ali bir kişi, İstanbul ise bir şehir olarak tanımlanır.
- Çözümlemeli Anlamlandırma (Disambiguation): Çok anlamlı kelimelerin anlamını bağlama göre çözer. Örnek olarak "Elma yedi" cümlesinde "yedi" kelimesi, "yemek" fiili anlamında kullanılıyor.
- Özetleme (Summarization): Uzun metinleri kısa ve öz bir şekilde özetler. Örnek olarak bir makaleyi birkaç cümleyle içeriğini eksiltmeden ana fikri anlatacak şekilde özetler.
- Soru Yanıtlama (Question Answering): Verilen bir soruya, metin ya da bilgiye dayalı doğru bir yanıt oluştur. Örnek olarak "Türkiye'nin başkenti neresidir?" sorusuna "Ankara" yanıtını verir.
Doğal Dil İşlemenin Geleceği
Günümüzde NLP, yapay zeka ile hızla gelişmekte ve diller arası bariyerleri aşmak, insan-makine etkileşimlerini kolaylaştırmak için büyük bir potansiyele sahiptir.Doğal dil işleme de kelimeler ve ifadeler bağlama göre farklı anlamlar taşıyabilir ve bu bağlamsal farkındalık makineler için zordur. Aynı zamanda dillerin kendine özgü yapıları, lehçeleri ve anlamlandırma kuralları, NLP için büyük bir zorluk oluşturması gibi etkenlere rağmen özellikle derin öğrenme ve genş dil modelleri (LLM) gibi teknolojilerle NLP'nin gücü sürekli artmaktadır. NLP'nin en önemli kullanım alanlarından biri de büyük dil modelleridir (LLM). Bir LLM, derin öğrenme algoritmaları kullanarak insan dilini anlamaya ve işlemeye odaklanır.
Büyük Dil Modeli (Large Language Model- LLM)
Büyük dil modelleri (LLM), doğal dil işleme (NLP) görevlerini yerine getirebilen, devasa boyutlarda eğitilmiş yapay zeka modelleridir. LLM'ler, çok büyük miktarda metin veri seti üzerinde eğitilerek, insanların girdilerine yanıt olarak anlamlı metinler oluşturma yeteneğine sahiptir. Buradaki kilit nokta "dil" olduğundan, LLM'ler yazılı dili anlama, analiz etme ve üretme üzerine uzmanlaşmıştır. LLM'ler genellikle milyonlarca, hatta milyarlarca parametre içerir ve bu parametreler aracılığıyla dilleri anlamada ve üretmede yüksek performans gösterirler.
Büyük dil modellerin temel özellikleri ve çalışma prensipleri:
- Eğitim Süreci: LLM'ler, geniş metin veri setleri (kitaplar, makaleler, web sayfaları vb.) üzerinde eğitilir. Eğitim sürecinde model, her cümlenin olası bir sonraki kelimesini tahmin etmeye çalışır. Bu süreç, modelin dilin kalıplarını ve ilişkilerini öğrenmesine olanak tanır.
- Transformers ve Attention Mekanizması: LLM'lerin çoğu, özellikle GPT modelleri, transformer mimarisi kullanılarak geliştirilmiştir. Transformer'lar, veri içindeki önemli kısımlara odaklanmayı sağlayan "attention" mekanizmasıyla çalışır. Bu mekanizma, bir cümledeki her kelimenin diğer kelimelerle ilişkisini öğrenir ve daha iyi bir anlam çıkarımı sağlar.
- Devasa Parametre Sayıları: Bu modellerdeki parametreler, dildeki kalıpları ve yapıları öğrenmeyi sağlayan ağırlıklar ve kat sayılardır. Büyük modellerde bu parametrelerin sayısı milyarlarca olabilir, bu da onların dilin karmaşık yapılarını ve nüanslarını öğrenmelerini sağlar.
- İnce Ayar (Fine-tuning): Büyük dil modelleri genellikle geniş bir veri seti üzerinde önceden eğitildikten sonra, belirli bir görev için ince ayar yapılabilir. Bu süreçte, modelin performansı daha spesifik bir kullanım senaryosuna göre optimize edilir. Örneğin, bir dil modeli genel dil bilgisi öğrenirken, daha sonra hukuki metinler üzerinde eğitilerek hukuk alanında daha iyi sonuçlar verebilir.
- Çok Yönlülük: Büyük dil modeller, çeşitli dil görevlerini gerçekleştirebilirler. Metin oluşturma, metin tamamlama, metin çevirisi, özetleme ve soru yanıtlama gibi görevleri yapabilir.
Büyük Dil Modellerin Yaygın Örnekleri
GPT-3: OpenAI tarafından geliştirilen, 175 milyar parametreye sahip bir büyük dil modelidir.
GPT-4: OpenAI tarafından geliştirilen, 1.7 trilyon parametreye sahip bir büyük dil modelidir.
BERT: Google tarafından geliştirilen ve doğal dil işleme görevlerinde sıklıkla kullanılan bir modeldir.
T5 (Text-to-Text Transfer Transformer): Google'ın çok yönlü bir dil modelidir.
Bu modellerden ve modellerin teknolojilerinden kısaca bahsedelim.
Generative Pre-trained Transformer (GPT)
GPT-3.5 ve 4 temelini oluşturan GPT “Generative Pre-trained Transformer” kısaltmasıdır. İlk olarak 2018 yılında OpenAI firması tarafından duyuruldu. Türkçeye “Üretken Önceden Eğitimli Dönüşüm” diye tercüme edebiliriz. Bu kütüphanesinin hayatımıza girmesinden çok uzun zaman önce geliştirilmesine başlandı. GPT kütüphanesinin geliştirilmesi Generate AI, Pre-trained ve en son 2017 yılında Google tarafından yazılan transformer ile tamamlandı. Her harfinde derya diyebilecek kadar çalışma olan büyük dil modellerini harf harf inceleyelim.
G- Generative AI:
Generative AI modelleri kullanarak imaj ve yazı oluşturma yeteneğine sahip bir yapay zekâ yaklaşımıdır. Bu modeller sisteme girilen verilerin yapılarını ve desenleri öğrenerek benzer özelliklere sahip yeni veriler üretir. Aslında oluşturduğu çıktı ile girdi arasındaki benzerlik ona bir esinlenme imkânı verir. Yeni hikâye, şiir gibi içerikleri böylece üretme imkanına sahip olur.
P - Pre-trained:
Pre-trained olarak ifade edilen “önceden eğitilmiş” model, benzer bir sorunu çözmek için başkası tarafından oluşturulan ve büyük bir veri kümesi üzerinde eğitilen bir modeli veya kayıtlı ağı ifade eder. Yapay zekâ ekipleri, sıfırdan bir model oluşturmak yerine, başlangıç noktası olarak önceden eğitilmiş bir modeli kullanabilir. Başarılı büyük ölçekli önceden eğitilmiş dil modellerine örnek olarak Google tarafından geliştirilen BERT (Bidirectional Encoder Representations from Transformers) ve OpenAI tarafından geliştirilen GPT-n serisi verilebilir.
T - Transformer:
Transformer derin öğrenme mimarisidir. 2017 Google firması tarafından duyurusu yapıldı, Transformatör ile LLM kütüphanesinin son halkası böylece tamamlandı. En basit açıklaması verilen bir veriyi kelimelere ayırıp daha önceden oluşturulan bir tablodan bakılarak bir vektöre dönüştürülür.
BERT
Bidirectional Encoder Representations from Transformers kelimelerin baş harflerinden oluşan BERT Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri olarak tercüme edebiliriz. BERT, Google tarafından geliştirilen transformatörü kullanarak geliştirildi. Doğal dil işlemedeki (NLP) en büyük zorluklardan biri eğitim verilerinin eksikliğine çare olarak geliştirilen en başarılı doğal dil işleme yaklaşımıdır. BERT, GPT ile rekabet edebilir belki birçok alanda öne geçebilir.
Büyük dil modeller, dille ilgili karmaşık görevlerde oldukça başarılı olmalarına rağmen, gerçek dünya bilgilerini kavrama konusunda sınırlı olabilirler. Bu nedenle bazen yanlış veya mantıksız cevaplar verebilirler. Ayrıca modellerin eğitimi ve çalıştırılması yüksek derecede hesaplama gücü gerektirir. Son olarak eğitildikleri verilerdeki yanlılıkları öğrenebilir ve bu da yanlış veya önyargılı cevaplar üretmelerine neden olabilir.
Kaynaklar: