
ChatGPT, OpenAI tarafından geliştirilen ve doğal dil işleme teknolojileriyle donatılmış, GPT (Generative Pre-trained Transformer) mimarisi üzerine kurulu bir dil modelidir.
2023 ve 2024'te en önemli gelişmelerden biri şüphesiz Yapay Zekaydı.
ChatGPT’nin insanlar gibi metin oluşturması dikkat çekici ve anlaşılması güçtür. Eğer ChatGPT ile biraz olsun vakit geçirdiyseniz salt bilgiden, yoruma dayalı türlü cevaplar aldığınızı göreceksiniz. Bunu nasıl başarıyor? Bu temel soruya cevap bulmadan önce şunu belirtmeliyim ki ChatGPT arkasındaki mühendislik ve bilgi birikimi, felsefeden insan beynine çoğu şeyi kapsayan mühendisliğin en etkili yansımasından biridir.
Yazımın uzun ve yorucu olabileceğini belirtmek istiyorum. Olup bitenlere kuş bakışı bakacak olsam da bazı mühendislik detaylarından bahsedeceğim. İlaveten detayını okuyucunun araştırmasına bırakacağım bölümler olacak. Yazımda GPT-2 modelini kullanarak Wolfram Dilinde ve Python Dilinde görselleştirmeler mevcut. Yine yazım boyunca OpenAI’ın ChatGPT’sini baz alacağım. Belki de ilerleyen zamanlarda rekabet veya başka nedenlerden böyle bir şirket kalmayacak -ne de olsa bundan 10 sene önce OpenAI da Yapay Zeka’nın geleceğini, olası risklerini ve etikliğini araştırmak üzere kurulan ve “kar amacı gütmeyen” bir kuruluştu-. Bu yüzden ChatGPT sadece bir örnek niteliğinde olacaktır. Amacım ChatGPT arkasında olup bitenlerin kaba taslağını “yüzeysel” aktarmak ve ardından bu olup bitenlerin nasıl ve neden bu kadar başarılı olduğunu araştırmak. Pratikte bir şeylere sahip olsak da teorikte bizim bile anlayamadığımız noktalar mevcut.
Bahsetmem gereken ilk şey ve özünde en temel şey, ChatGPT’nin sahip olduğu metnin makul bir devamını üretmek olduğudur. ”Makul” derken bahsettiğim; yazılan bir metnin herhangi biri tarafından beklenebilecek olası devamıdır.
Örneğin elimizde `Reducing all random activity in the real world to...` cümlesi olsun
ChatGPT milyarlarca sayfalık metni tarayabilir ve bu metine benzeyen örnekler bulabilir. Ancak, bu işlem gerçek metni anlamak yerine, "anlam açısından eşleşen" “unsurları” arar. Yapay zeka, belirli kelimelerin metinde ne sıklıkla geldiğini belirleyebilir ve ardından olasılıklarla birlikte metni takip edebilecek kelimelerin sıralı bir listesini üretebilir.
Reducing all random activity in the real world to…

Üzerinde durulması gereken nokta şu ki, ChatGPT metin yazmaya başladığında aslında yaptığı şeyin devamlı olarak şimdiye kadar olan metne bakarak devamının nasıl olacağıyla alakalı olasılık hesaplaması yapmak ve her seferinde yeni kelime eklemektir.
Pekala, bir sonraki kelimenin ne olacağına dair elimizde bir olasılık listesi var fakat hangisini seçmeliyiz? İlk bakışta en yüksek olasılığa sahip olanı seçmemiz gerektiğini düşünsek de, bunu yapmamalıyız. Çünkü her zaman en yüksek olasılığa sahip kelimeyi seçersek metnimiz matematiksel olarak kusursuz olacaktır. Hiçbir zaman yaratıcılık göstermeyen (hatta zaman zaman kendini tekrar eden) sade bir metin olacaktır. Bazen alt sıralardaki metni seçersek daha “yaratıcı” bir hale gelecektir. Rastgelelik durumu söz konusu olduğunda aynı istemi(promt’u) ne kadar kullansak da farklı metinler elde edebiliriz.
Düşük olasılığa sahip kelimelerin ne sıklıkla kullanılacağını belirttiğimiz “sıcaklık(temperature)” adı verilen bir parametremiz var. Bir metin oluşturmak için en etkili değerin “0.8” olduğu belirlendi. Vurgulamak istediğim nokta ise burada herhangi bir teorik dayanağın olmadığıdır(şimdilik veya en azından bizim henüz bilmediğimiz); yalnızca pratikte neyin işe yaradığı ile ilgili bir mesele. Teorik dayanağının olmaması yanlış olduğu anlamına gelmez; teorik fizikten aşina olduğumuz üstel dağılımlarla bunu görebiliyoruz.
Şimdilik kullanacağım dil modelini kara kutu olarak kabul edip. Modelden olasılığı en yüksek 5 kelimeyi getirmesini isteyelim.

Anlaşılması daha kolay hale getirelim

Her seferinde cümleye ne eklediğine göz atalım

0 sıcaklık değerinde buna metin olarak devam edersek nasıl bir sonuçla karşılaşırız? Oldukça anlamsız ve kendini tekrarlayıcı oluyor

Peki her zaman en üstte olan kelimeleri seçmesini istemezsek ( sıcaklık değerini artırırsak )?

Şimdi ise aynı istemi ne kadar yazarsanız yazın farklı sonuçlarla karşılaşacaksınız

0.8 sıcaklık değerinde, çok sayıda olası sonraki kelime mevcut. n−1 güç yasası olarak adlandırılan bir dil özelliği vardır. Dilin genel istatistiklerinde bir kelimenin bir önceki kelimeye bağlı olarak gelecek olasılığın, bir güç fonksiyonu ile azaldığı bir desen gözlemlenir. Bu azalan desen çok karakteristik olan; logaritmik ölçekte düz bir çizgidir ve olasılıkların azalma hızının düzenli ve belirgin olduğunu gösterir.(Zipf’s Law loglog )

Olasılıkların Sağlanması
Pekala, ChatGPT kelime bazında neler yapıyor bunu gördük. Şimdi ise harf olasılığının ne olması gerektiğini nasıl hesaplayabiliriz?
Temel mantıktan sapmadan, herhangi bir metin alarak buradaki harf olasılıklarını gözleyerek ve ufak tefek oynayarak hesaplayabiliriz.
Herhangi bir kelime seçersek ve içerisindeki harfleri saydırırsak eğer, örneğin “book” kelimesi için Wikipedia makalesinin içerisinde çıktımız bu şekildedir
![]()
Bu liste hangi kelimeyi verdiğimize göre değişecektir ve şüphesiz ‘o’ makale içerisinde daha yaygındır çünkü “book” kelimesinin içerisinde geçmektedir.
Bu liste ile rastgele bir harf dizesi oluşturalım.
![]()
Bunlar sanki anlamlı kelimeymiş gibi boşluklar ekleyelim.
![]()
Kelime uzunlukları dağılımının İngilizce ile aynı olmasını hesaba katalım(Diğer taraftan boşlukların ne sıklıkla kullanıldığı anlamına da gelebilir veya ikinci bir parametre olarak hesaba katılabilir)
![]()
Hala gerçek bir kelime elde edemedik. Şu ana kadar yaptıklarımız olasılık içerse de hala yeterli değil, harfleri rastgele koymaktan daha fazlasını yapmalıyız.
Harflerin kendi başlarına olasılıklarını çıkaralım

Ve harf çiftlerinin olasılıklarını gösteren 2-gram grafiği var.(2-gramlar, genellikle “bigram” olarak adlandırılır ve birbiri ardına gelen iki harfin bir arada incelenmesini sağlar. Bu, metin analizinde harf çiftlerinin birlikte nasıl ve ne sıklıkla kullanıldığını anlamamıza yardımcı olur)

Grafikte görüldüğü üzere İngilizcede “q” harfinden sonra genelde “u” harfi gelir. “u” harfi dışında kullanılan, çok nadir başka harf içeren kelimeler var (Hatta bunlar özel kelimelerdir. Örn: “Qatar” veya dile başka dillerden giren kelimeler). Bu demektir ki “q” harfinden sonra “u” harfi gelmeden kullanımı mevcut değildir. Bu grafiğe bakarak yaptığımız çıkarımdan bir örnektir ve olasılık spektrumunu daha tutarlı hale getirmeye devam ederiz. 2-gram grafiği ve diğer değerleri göz önünde bulundurarak oluşturduğumuz gerçek anlam içeren kelime barındıran cümlemiz:
![]()
Kaynak arttıkça aldığımız verim artacaktır. n-gram olasılıkları birbirlerini tamamlayan yeni n- gramlar oluşturursak daha iyi çıktılar elde ederiz. İşte bazı örnekler:

İngilizcede kullanılan yaklaşık 40 bin kelime vardır. Dijital kitaplık ve kitaplara (Milyarlarca kelimeye ev sahipliği yapan birkaç milyon kitap varsayalım) yeteri kadar bakabilirsek şayet; kendimize hangi kelimelerin hangilerinden sonra ne sıklıkla geldiğine ve bunların görünme olasılıklarıyla çok daha verimli “cümleler” elde edebiliriz. Aşağıda bu çıkarımımızın bir örneğini verdim.
![]()
Cümlenin anlamsız olması beklenen bir şeydir. Daha iyisini nasıl yapabiliriz? Tıpkı harflerde olduğu gibi her kelimeyi ayrı olasılıklarla değil, kelime çiftlerinin olasılıklarını da hesaba katarsak ve yeterince uzun n-gramlar daha iyi bir sonuç elde edeceğimiz açıktır. Buraya kadar olan düşünceleri kullanarak “bir ChatGPT” hayal edilebilir fakat her kelime çiftinin 2-gramı bile milyarları buluyor. Yalnızca olasılıklar ile “düzgün” bir kompozisyon yaratmaya çalışırsak bu olasılıkları ortaya çıkarabilecek kadar yeterli İngilizce metin bile yazılmadı. Bu metinleri yalnızca olasılık kullanarak tahmin etmemizin hiçbir yolu yok. 20 kelimelik bir “metin parçasına” ulaştığımızda olasılık sayısı evrendeki parçacıkların sayısından daha fazla oluyor.
Bu noktada bir adım ileri giderek “Büyük Dil Modeli (LLM) (Large Language Model)” adı verilen tam da bu olasılıkları tahmin etme konusunda iyi iş çıkaran “Model” kavramı bulunur.
MODEL
Model, karmaşık ve geniş veri setlerinden öğrenerek belirli görevleri gerçekleştirebilen matematiksel bir yapıdır. Dil modelleri, büyük miktarda metin verisini analiz ederek dil yapısını ve bağlantılarını öğrenirler. Ardından, öğrendikleri bilgileri kullanarak metin üretme, soru cevaplama, çeviri yapma gibi çeşitli görevleri yerine getirebilirler. Özetle “Model” terimi genellikle genel bir yapı veya belirli bir görev için eğitilmiş bir algoritmayı ifade ederken, "Büyük Dil Modeli(LLM)" daha geniş bir dil bilgisi ve kapasiteye sahip olan, büyük veri setleri üzerinde eğitilmiş olan spesifik modelleri ifade eder.
Modelin ne olduğunu bir analoji ile açıklayayım; Galileo’nun zamanında yaptığı gibi Pisa Kulesi’nin her katından atılan bir güllenin yere ne zaman düşeceğini bilmek istiyoruz. Her kattan atıp sonuçların bir tablosunu oluşturabilirsiniz. Veya teorik bilimin özü olan şeyi yaparak; sadece her durumu ölçmek yerine, cevabı hesaplamak için bir tür prosedür sağlayan model yaparız.
Top güllesinin her kattan düşmesi sonucu idealize edilmiş bir veri grafiğimiz olsun.
Hakkında veri sahibi olmadığımız bir konumdan atıldığında ne kadar sürede yere düşeceğini hesaplamak istiyor olalım.
Hiçbir şey bilmeden bu hesaplamayı yapabilmenin bir yolu var mıdır? Fizik yasasını kullanacağız tabii ki ama altında yatan yasanın ne olduğunu bilmediğimizi varsayalım.

Evet, cevap olarak noktaları takip eden bir çizgi çekersek eğer ortalama olarak herhangi bir kattan güllenin düşme süresini tahmin edebiliriz bildiğiniz üzere.
Matematiksel bir ölçümün basit şeylerle iyi uyum sağladığı gerçeğine alışkınız. Bu çizgi için a + bx + cx2 dersek bu grafik için uyumlu olabilir.
Fakat a + b/x + csin(x) kullanırsak dalgalı bir görüntü elde ederiz.
Bu örneği vermemin nedeni ise hiçbir zaman “modelsiz model” olmayacağını belirtmek. Çünkü çizgiyi bir boş kağıda çizmiyoruz. Her modelin altında yatan bir mantık, gereklilik ve ayar yapabilmek için bazı “düğmeler” vardır. ChatGPT ise bunlardan yaklaşık 175 milyar adet kullanır.
İlgi çekici olan nokta ise yukarıda bahsettiğim “makul bir metin” yaratmak için ChatGPT’nin yalnızca bu kadar parametreyle bize “bir sonraki kelime” verebilecek olasılıkları hesaplayan bir model oluşturmaya yeterli olmasıdır.
Görsel Model
Model örneğinde, verdiğim matematiksel verilerden türetilen bir model örneği sunulmaktadır. Ancak, insan dilini taklit etmek için sadece bu tür modeller yeterli değildir. İnsan dilinin karmaşıklığı ve derinliği, mevcut matematiksel modellerle tam olarak yakalanamaz. Bu nedenle dilin doğasını daha iyi anlamak ve taklit etmek için görsel modellere başvurulmuştur.
Rakamları tanımak istediğimizi düşünelim. Yapabileceğimiz en iyi şeylerden biri bu rakamların farklı yazım şekillerini bulup örneklem uzayını çoğaltmak olur.
Sonrasında ise rakamları birbirinden ayırt etmek ve tanımak için piksel piksel karşılaştırıp bazı sonuçlar elde edebiliriz. Ancak insanlar olarak kesinlikle çok daha iyisini yapabiliyoruz gibi görünüyor. Çünkü rakamları el yazısıyla yazılmış olsalar bile, hala tanıyabiliyoruz ve değişik çarpıtmalara da sahibiz.

Yukarıdaki sayısal liste için bir model yapmak istersek gri, siyah ve beyaz piksel değerlerine bakarak bize hangi rakama ait olduğunu söyleyen bir model oluşturabilir miyiz? Evet bunun mümkün olduğu ortaya çıktı ve hiç şaşırtıcı olmayan şekilde, basit değil. Küçük bir örnek yarım milyon matematik işlemini içerebilir. Fakat yine de herhangi bir fonksiyon ile beslersek sayıyı bulabiliriz. Böyle bir fonksiyonu nasıl oluşturacağımız ise insan beyninden esinlenilerek oluşturulmuş “Yapay Sinir Ağı” fikrindedir.
Elle yazılmış rakamların hangisinin hangi rakama denk geldiğini ve görüntüleri beslediğimiz piksel değerlerinin hesaplamalarını kara kutu olarak kabul edelim şimdilik.
Yapay Sinir Ağı’na geçmeden önce ise düşünülmesi gereken nokta şudur: Elle yazılmış bir sayı dizesinden bir rakam alıp devamlı bulanıklaştırırsak bir süre sonra yanlış sonuç vermeye başlayacaktır. Buradaki sınır nedir? Gerçekte ne oluyor da tanımamaya başlıyoruz? Ancak amacımız insanların görüntüleri tanımada neler yapabileceğine dair bir model üretmekse, sorulması gereken asıl soru, bir insana bu bulanık görüntülerden birinin nereden geldiğini bilmeden sunulması durumunda ne yapacağıdır. Doğruluğunu teyit edebilecek matematiksel bir model veya veriye sahip miyiz? Veriye bile sahip değiliz. Herhangi bir matematiksel model veya veri olmadığından dolayı burada doğrulama kıstası biz oluyoruz. Eğer makinamız rakamı bizim tanımlayabildiğimiz noktaya kadar ve bizim tanımlayabildiğimiz şekilde tanımlıyorsa iyi bir modele sahibiz diyebiliriz.
Yapay Sinir Ağları
Yapay Sinir Ağları insan beyni gibi kendi kendine öğrenebilen muhteşem yapının bilgisayar ortamına adapte edilmiş halidir. Yukarıda bahsettiğim gibi beynin bir modelidir. Amacımız ise açık bir şekilde var olan nöronları harekete geçirerek, geliştirerek verilen girdiyi işleyerek karar mekanizmasına dönüştürmek.
Beyindeki nöron yapısını hatırlayalım:

Akson, üretilen darbeleri iletici kanaldır ve çıkıştır. Dendrit’ler ise alıcıdır ve diğer nöronlardan gelen iletileri alır. Sinaps, iki nöronu bağlayıcı yapıdır.
Bu kimyasal yapıda nöron içerisindeki Stoplazma −85mV ile polarize durumdadır.
Bu değer −40mV ise “Uyarma”; −90mV ise “Bastırma” uygulanır.
(Uyarma için bir eşik (threshold) değeri olduğu açıktır.)
Bu bir nöronun uyarılması için en temel anlatımdır.
Şimdi ise bu yapının modelleme karşılığına gelelim
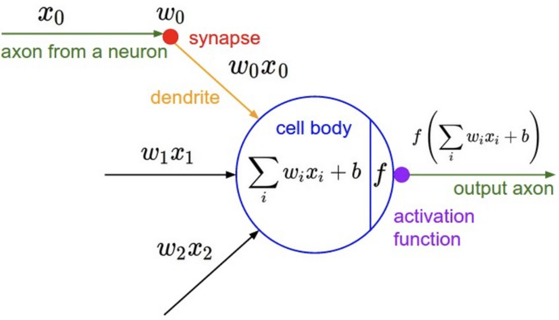
Bu gördüğünüz bir nöronun matematiksel modelidir.
x girdi, ω ağırlık(threshold için gerekli), b ise bias değeri(aktivasyon fonksiyonunun shift edilmesini sağlar, sebebi ise giriş değeri “0” olduğunda öğrenme gerçekleşmez. Bias değeri ise giriş değerlerini sıfırdan farklı tutmak için bir parametredir.)
Aşağıda 3 katmanlı bir Yapay Sinir Ağı mevcut(Giriş ve Çıkış katmanları hariç). ChatGPT bunlardan yaklaşık 175 milyar(nöron) adet kullanır.

4x5 + 5x5 + 5x5 + 5x5 + 5x3 hesap sonucu bize ω(Ağırlık değeri) verir.
5 + 5 + 5 + 3 ise bize b(bias) değerini verir.
Burada ω ağırlığının nasıl belirleneceği, katman sayısının ne olacağı, yapay sinir ağlarının nasıl eğitileceği. Dolaysıyla performans, ölçeklenebilir, optimizasyon gibi konularla ilişkilidir. Daha detaylı araştırmak isteyen kişiler Nöral Ağ (Neural Network) konusuna detaylı bakabilir. Bu tarz bir sinir ağı görüntüyü nasıl “tanıyabilir”? "Çekicilik Kavramı" (Notion Of Attractors) konusudur, sinir ağlarının nasıl çalıştığı ve belirli veri setlerinde nasıl öğrenme sağladığına dair daha derinlemesine bilgi sunabilir. Çekicilik Kavramı, ağın belirli bir hedefe veya sonuca doğru nasıl evrildiğini ve bu süreçte nasıl davrandığını anlamamıza yardımcı olabilir.
Gömülü Temsiller (Embeddings)
Gömme kavramı ise bir kelimenin veya kelime öbeğinin, Öklid uzayında temsil edilmesidir. Bu temsil kelimenin anlamının yakalamak için tasarlanmıştır ve kelimeyi Öklid uzayında bir noktaya yansıtır. Bu sayede kelime anlamı vektör uzayında diğer kelimelerle karşılaştırılabilir olur ve anlam bakımından yakın cümleleri yakalamak için kullanılan bir tekniktir.
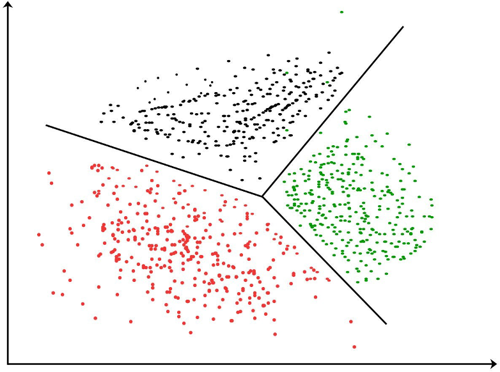
“Öklid (Vektör de olabilir)” uzaydaki her noktayı birbirlerine anlam olarak yakın kelime veya kelime öbekleri olarak düşünebiliriz. “Kitap” ve “Sözlük” kelimeleri yan yanayken; “Kitap” ve “Taş” kelimeleri birbirinden çok uzak olabilir. Bu kullanım bize cümlenin bağlamından kopmadan birbirlerine yakın kelimeler üstünde gezinerek “uygun” “bir sonraki kelime” seçiminde bize yardımcı olur. Teknik olarak uyguladığımız metot ise her kelimeye bir sayı atamaktır. Ve bu “Sınıflandırma”(Classification) 2 boyutludur.
ChatGPT’de 3 boyutlu bir classification kullanılmaktadır. 3 boyutlu bir sınıflandırma kullanmanın avantajı ise bize veri setindeki özelliklerin birbirleriyle olan ilişkilerini daha iyi yakalamasından gelir. Aşağıda 3 boyutlu bir örneği mevcut.
Bu Öklid uzayında ChatGPT’nin anlam ve bağlam olarak eşleşen “bir sonraki kelime”yi bulma arayışında gezindiğini ve bunu noktalar arası gezintiyi vektör ile gösterdiğimizi varsayarsak burada açıkça geometrik bir yasaya sahip değiliz. Bu olmayan yasa açık olmaktan çok uzaktır ve insan benzeri metin üretme konusunda edindiği iç davranışlar ampirik olarak (en azından henüz) çözülemedi.

Üretim Mucizesi
Anlama adımlarını temelde şu şekilde yapar, belirtilen promt’u alır ve bunları temsil eden bir embedded -sayı dizisi- edinir. Sonrasında ise yeni bir embedded dizisi -sayı dizisi- üretmek için yapay sinir ağında, ağın öğrenme sürecindeki ağırlık değerlenin değişmesiyle birlikte çalışır.
Ardından bu yeni diziyi kullanarak ondan farklı olası sonraki kelimeler için olasılık hesabı yapar.
Kritik bir nokta, bu boru hattının her parçasının, ağırlıkları ağın uçtan uca eğitimi ile belirlenen bir sinir ağı tarafından uygulanmasıdır. Başka bir deyişle, aslında genel mimari dışında hiçbir şey "açıkça tasarlanmamıştır"; Her şey sadece eğitim verilerinden "öğrenilir".
Eğer bu karar verme sürecince hangi yolu neden tercih ettiğini incelemek istiyor olsaydık kullandığı büyük matris ve Yapay Sinir Ağı’nın kendi kendine öğrenme durumu dolayısıyla bunu yapamazdık. En nihayetinde Yapay Sinir Ağını kodlayanlar olsak da onu anlayamıyoruz. Eğer uzaklaşıp bu büyük matrise bakıyor olsaydık belki de fMRI ile ölçülen bir beyin aktivitesi görürdük kim bilir.
Peki ChatGPT’nin yukarıda gösterdiğim basit adımlarla insan benzeri cümleleri ve yapıları nasıl oluşturduğunu temel düzeyde anlatmış olsam da bu oldukça şaşırtıcıdır çünkü böyle bir ağın tüm dilbilgisi kurallara, inceliklere ve bunu çoğu dilde yapabiliyor olması her halükarda şaşırtıcı.
Çünkü yukarıda da bahsettiğim gibi biz dil bakımından takip edilmesi ve uygulanması gereken kuralları söylemeden ve biz bile herhangi bir dil “yasasına” sahip olmadan ”konuşma” ve “anlama” gibi bizim bile sonradan öğrendiğimiz şeyleri yine aynı insanlar gibi kendi içindeki öğrenim analojisiyle “bir şekilde” çözmesi nereden bakarsak bakalım şaşırtıcı.
Hesaplamalı İndirgenemezlik (Computational Irreducibility)
Genel anlamda ChatGPT’nin akış diyagramından, algoritmaların hangi konuları içerdiğinden bahsettim. Son olarak "Hesaplamalı İndirgenemezlik" terimi, genellikle karmaşık bir sistem veya modelin tam olarak basit veya özet bir forma indirgenemediği durumlar için kullanılır. Bu, hesaplamaların, modelin veya sistemin doğasından kaynaklanan zorluklar nedeniyle daha basit bir formda ifade edilemeyebileceği anlamına gelir kısaca. (Büyük Veri Analizi, Kuantum Mekaniği, Nümerik Simülasyonlar)
İnsan beyninin herhangi bir matematik hesabı yapması özel bir çaba gerektirir. Bilgisayarlar bu konuda insanlardan daha iyidir bu yüzden indirgenebilir ama zor olan hesaplamaları günümüzde onlara bırakmayı tercih ediyoruz. Ancak bahsettiğim gibi bilgisayarların bile hesaplayamadığı özel durumlar var (Örn: Traveling Salesman Problem (Gezgin Satıcı Problemi) (TSP)).
İndirgenemez hesaplamalarda mesele şu ki, olmayacağını düşündüğümüz hiçbir “özel” durumu açık bir biçimde hesaplayarak bulmadığımız sürece ne olup bittiğini garanti edemiyor olmamız.
Sistemin öğrenebilirliği, eğitilebilirliği ve hesaplama yetenekleri arasında ise temel ve hiç önemsiz olmayan bir korelasyon bulunur. Eğer sistemin hesaplama yeteneklerini sonuna kadar kullanmasını isterseniz, bu isteğinize istinaden bir o kadar hesaplamalı indirgenemezlik olgusu üretecek çünkü istenen durumun her çıktısını üretmek zorunda kalacak, bu durumda da eğitilebilir olmayacak. Yani hilesiz bir paranın yazı tura atılması ile yazı veya tura gelmesinde beklenen matematiksel sonuç teoride ½ iken aslında pratikte hiçbir zaman tam olarak ½ değildir. Matematikte kullanılan “hilesiz” ibaresi bile aslında indirgenemez hesaplamanın önünü kesmek için çizgi çekmektir.
Buradan çıkarılması gereken en önemli sonuç günümüzde ChatGPT, ben bu yazıyı hazırlarken tanıtımı yapılan Google’ın Yapay Zeka’sı “Gemini” ve daha birçok, insan benzeri yorumlama ve yeteneğe sahip yapay zeka ortaya çıkarken bizim yapabildiğimiz ama bilgisayarların yapamayacağını düşündüğümüz makale yazmak gibi görevlerin, hesaplama açısından düşündüğümüzden daha kolay olduğudur. Dille uğraşmanın ve makale yazmanın hesaplama açısından aslında “sığ” bir sorun hale gelmesi bize dili bir teoriyle temellendirebilmeye yaklaştırıyor. Dil burada konu çerçevesinde mecburi bir örnektir, potansiyel gelişim konuları ve kesinlikle bilim adına umut vaadedici, belki de çözülmek için Yapay Zeka desteğini bekliyor olan alanlar mevcut.
Çok da uzak olmayan bir zaman diliminde Yapay Zeka bizi, biz de onu daha iyi anlayacağız. Son yüzyıllarda "saf, yardımsız insan düşüncesi"nin erişebileceği sınırların ötesine geçmemize ve fiziksel ve hesaplamalı ortamda var olanın daha fazlasını insani amaçlar için gerçekleştirmemize olanak sağlayan şey, hem pratik hem de kavramsal araçların kullanımıdır. Evren.
Kaynakça:
- Wolfram Neural Net Repository - resources.wolframcloud.com/NeuralNetRepository/resources/LeNet-Trained-on-MNIST-Data/ Convolution Layer reference.wolfram.com/language/ref/ConvolutionLayer.html
- Future Internet | Free Full-Text | ChatGPT and Open-AI Models: A Preliminary Review. (n.d.) www.mdpi.com/1999-5903/15/6/192
- “ChatGPT — The Era of Generative Conversational AI Has Begun” (Week #3 - article series). (n.d.) www.linkedin.com
- How Does ChatGPT Actually Work? An ML Engineer Explains. (n.d.) www.scalablepath.com How to build a Sustainable ChatGPT Server Architecture?. (n.d.) www.diskmfr.com ChatGPT, the rise of generative AI. (n.d.) www.cio.com
- How ChatGPT gets Stitched with Cloud Services?. (n.d.) itibaren itechnolabs.ca
- ChatGPT Prompt Engineering: Crafting Better AI Dialogues. (n.d.) itibaren www.pixelhaze.academy/blog/chatgpt-prompt-engineering
- How ChatGPT works and AI, ML & NLP Fundamentals | Pentalog. (n.d.) www.pentalog.com/blog/tech-trends/chatgpt-fundamentals/
- What Is ChatGPT Doing … and Why Does It Work? (n.d.) https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
- Chapter 6: Starting from Randomness www.wolframscience.com/nks/chap-6--starting-from- randomness/#sect-6-7--the-notion-of-attractors
- ChatGPT: Understanding the ChatGPT AI Chatbot. (n.d.) www.eweek.com/big-data-and- analytics/chatgpt/
- Opinion Paper: “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy -
- ScienceDirect. (n.d.) www.sciencedirect.com/science/article/pii/S0268401223000233
- Chapter 12: The Principle of Computational Equivalence (n.d.)
- www.wolframscience.com/nks/chap-12--the-principle-of-computational-equivalence/
- How ChatGPT actually works (n.d.) https://www.assemblyai.com/blog/how-chatgpt-actually- works/
- https://finnaarupnielsen.files.wordpress.com/2013/10/brownzipf.png?w=487
- https://preview.redd.it/snny9gfpqpdz.png? width=960&crop=smart&auto=webp&s=dc161cb38f6f5ecdaea3d6bcd263a0ec824cec80
- https://course.elementsofai.com/static/4_1-mnist-9fe2c1b5d633ca5e9d592a0e0b8262d4.svg
- https://www.researchgate.net/figure/Neuron-structure-in-the-human-brain-Reprinted-with- permission-from-4_fig2_317028037
- Ensemble Methods for Pedestrian Detection in Dense Crowds - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/Mathematical-model-of-a- biological-neuron_fig7_336675545 [accessed 04 Dec, 2023]
- https://tikz.net/neural_networks/ — https://tikz.net/wp- content/uploads/2021/12/neural_networks-001.png
- https://towardsdatascience.com/important-topics-in-machine-learning-that-every-data-scientist-must-know-9e387d880b3a
- https://miro.medium.com/v2/resize:fit:640/format:webp/0*LyxxcclWH3_zY2u3.gif




















































































































































{kind=link}
{kind=link}