Bu paylaşımımda sizlere Elasticsearch ile ilgili önemli olduğunu düşündüğüm iki konudan bahsetmek istiyorum. İlk konumuz indekslerimizi birden fazla parçaya bölerek saklamamızı sağlayan Shard’lar, diğeri ise metinsel verilerimizi indekslemeden önce işlenebilir hale getirecek Analyzer’dır. Ama öncelikle Elasticsearch ile ilgili ufak bir bilgi vermiş olayım.
ElasticSearch Nedir?
Elasticsearch Apache Lucene kütüphanesini kullanan JAVA tabanlı veri kaydetme, indeksleme ve sorgulama yapmamıza olanak sağlayan NoSQL veri tabanı, arama motoru ve analiz aracıdır. Apache Lucene düz metinlerin indekslenmesi ve sorgulanmasını sağlarken, bu kütüphane kullanılarak geliştirilen Elasticsearch yapısal(structured) verilerin işlenmesini sağlar. Elasticsearch JSON formatında veri/girdi kabul eder ve yine aynı formatta yanıt verir. Restfull API desteği vardır.
ELK Stack(Elasticsearch, Logstash, Kibana) platformunun merkezi bileşenini oluşturmaktadır. Elasticsearch dağıtık ve kolay ölçeklenebilir yapıya sahiptir, bu sayede büyük veri kaynaklarının hızlı işlenmesini sağlar. Veri okuma ve yazma işlemlerini büyük oranda bir saniye altında işleyebilecek seviyede bir performansa sahiptir.
İlişkisel veri tabanlarının bize sağladığı veriyi kaydetme, indeksleme ve sorgulama özelliklerinden farklılaştığı kısım metinsel veri üzerinde indeksleme yapması ve bu indekslenmiş verileri çok daha performanslı olarak sorgulayabilmemizi sağlamasıdır. Elasticsearch’e ait terimlerin ilişkisel veri tabanlarındaki karşılıklarını aşağıdaki Tablo-1’den bakabiliriz.

Shard Nedir?
İlişkisel veri tabanlarında da kullanılan Shard’lar özetle bir veri kümesinin parçalara ayrılarak saklanması ve yönetilmesini sağlar. Yani tek bir sunucuda veya bir node içinde bulunan verinizi farklı sunuculara veya nodelara dağıtılmasını sağlayabilirsiniz. Elasticsearch’de shardları Lucene indeksleri olarak tanımlayabiliriz yani veriyi indeksleyip sorgulamamızı sağlayan bağımsız arama motorları.

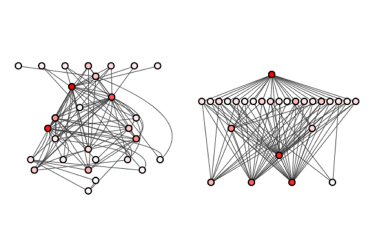
Yatay ölçeklendirmeyi sağlayan Shard doğru şekilde kullanılırsa performans artışı sağlayacaktır. Örnek üzerinden bunu daha iyi anlayabiliriz. Yukarıdaki sol resimde bir indekse bağlı tek bir Shard vardır, toplu olarak 100 adet veri geldiği durumda bu gelen verinin tamamının bir Shard tarafından işlenmesi beklenmektedir, bu işlemlerde zaman alacaktır. Ancak sağdaki örneğimizde bir indeks 4 farklı Shard’a bölünmüştür, verinin indekslenmesi sırasında eşit olarak görev paylaşımı yapıldığını düşünürsek her bir Shard’ın 25 adet veriyi paralel işleyerek bir önceki örneğe göre indeksleme daha hızlı tamamlanacaktır.
Veriyi yazma/indeksleme işleminde Shard sayısının fazla olmasının bizim için avantaj olduğunu gördük. Ancak veriyi sorgulamak istediğimizde Shard sayısının bizim için negatif etkisi olabilecektir. İsterseniz öncelikle veri sorgulamanın nasıl yapıldığını bakalım. Elasticsearch de sorgulama iki aşamadan oluşmaktadır birinci aşama verinin hangi Shard üzerinde olduğunu belirleme, ikinci aşama verinin bulunduğu konumdan okunması. Yine yukarıdaki görselle konuyu anlatırsak, sağdaki resimde bulunan her bir Shard kendi içinde sorgulama yapıp sonucu bu işlemi yöneten node’a iletecektir sonrasında yöneticimiz ilgili Shardlardan veriyi talep edecektir. Shardların bağımsız olarak yaptıkları her işlem sunucuda kaynak tüketimine neden olacaktır. Büyük bir indeks verisi farklı Shardlar ile küçük parçalara bölünürken indeks veri boyutu değişmiyor bile olsa, her bir Shard çalışması için gerekli kütüphaneleri ayrı ayrı çalışır hale getirmesi, dosya sistemine veri alması vb. işlemleri kendi özellerinde yapmaları gerekecektir. Sunucu kaynağının kısıtlı olduğu durumlarda olumsuz sonucu olacaktır.
Peki Shard sayısı kaç tane olmalıdır? Shard sayısının fazla olmasının yazma işleminde avantajlı, sorgulamada işleminde ise dezavantaj olduğunu gördük. Bu sayının önceden belli, tavsiye edilen bir değeri yoktur, ideal sayıyı ve veri boyutunu Elasticsearch kullanımına bakarak ve deneyimleyerek karar verilmesi daha doğru olacaktır.
Bu ana kadar bahsettiğimiz shardlar Primary Shard olarak isimlendirilmektedir. Birde yedek verinin saklanıp işlendiği Replica Shard vardır. Avantajını aşağıdaki resimle anlatacak olursak, Shard-1 in yer aldığı Node-1 de herhangi bir sorun meydana gelirse buradaki verilere Node-3 üzerinde yer alan Replica-1’den erişilebilir. Yine koşullara bağlı olarak veri indeksleme ve sorgulama işlemlerinde avantajları veya dezavantajları olabilir. Replica Shard’ların sayısını yine kendi ihtiyacımız doğrultusunda belirleyebiliriz. Elasticsearch en az bir tane Replica Shard oluşturmanızı, hatta bunun mümkünse farklı sunucu ve node da olmasını tavsiye etmektedir.

Analyzer
Ve artık Elasticsearch metinsel veriyi nasıl indeksliyor inceleyebiliriz. Bu işlemin baş kahramanı Analyzer’dır ve yaptığı işleme analiz denir.
Aşağıdaki resimde yer alan bir text metin indekslenmesi için geldiğinden veri Analyzer tarafından analiz işlemine alınır ve bu işlem sonucunda Inverted Index olarak isimlendirilen hangi kelimenin hangi metin/doküman da olduğu bilgisini içeren tablonun oluşturulması sağlanır. Bu veriyi kitapların arkasındaki dizin/indeks sayfası gibi düşünebilirsiniz. Kitapta bir kelimenin nerede geçtiğini bulmak için buraya baktığımız gibi, Elasticsearch’de bu tablo verisine bakarak aranan kelimeyi hızlı bir şekilde bulabilmektedir.

Elasticsearch’ün önemli bir parçası olan Analyzer aşağıda gördüğünüz üç ayrı bileşenden oluşmaktadır. Bu bileşenler metnin işlenmesi aşamasında sırayla çalışmaktadır.

Character Filter: Bu bileşen gelen metin içinde istemediğimiz karakterlerin filtrelenmesini veya değiştirilmesini sağlar. Örneğin; gelen metinde yer alan HTML taglerini silebilir veya Arapça rakamları (٠١٢٣٤٥٦٧٨٩) latin rakamlarına (0123456789) dönüştürebilirsiniz.
Tokenizers: Tokenizer’in görevi metni token/term/kelime olarak adlandırdığımız parçalara bölmektir. Örneğin metni aradaki boşluklara göre bölebilirsiniz veya bir e-mail adresini aşağıdaki şekilde parçalayabilirsiniz.

Token Filter: Son bileşenimiz ise artık gereksiz karakterler arındırılmış, küçük parçalara bölünmüş kelimelerden istenmeyenlerin çıkartılması yani indekslenmesini engellemek için kullanırız. Yukarıdaki e-mail örneğinde “com” kelimesini indekslememiz gereksiz olabilir bu durumda Token Filter’ı kullanabiliriz. Veya Eleasticsearch’ü hata logları için kullanıyorsak ve “System.NullReferenceException: Object reference not set to an instance of an object.” gibi bir hatayı indexlerken “to”, ”an”, ”of”, “not” gibi tokenları filtrelemek için kullanabiliriz.
Bu filtreleme işlemleri ihtiyacımıza göre özelleştirmek gerekmektedir. Bu bize indeksleme, sorgulama ve veri boyutlarında avantaj sağlayacaktır. Analyzer hem indeksleme sırasında hem de sorgulama aşamasında kullanılabilir. Örneğin; “This is fatal error” şeklinde bir hata mesajını indekslediğimizi düşünelim ve Tablo-2’deki gibi Inverted Index verilerimiz oluşsun. Sonrasında “fatal” kelimesini indekslerimizde “fatal” veya büyük harfle başlayan “Fatal” şeklinde bir arama yaptığımızda bize aynı sonucu verecektir.

Kaynaklar:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
https://medium.com/elasticsearch/introduction-to-elasticsearch-5d9e9f3f769e
https://codecurated.com/blog/introduction-to-analyzer-in-elasticsearch/
https://www.baeldung.com/java-shards-replicas-elasticsearch
https://tr.linkedin.com/pulse/elasticsearch-serisi-mimari-%C3%B6zellikleri-sharding-ve-scaling-tungut