Yapay zekâ artık sadece konuşan değil, düşünen bir sistem haline geldi. Ancak son yıllarda fark ettiğimiz bir gerçek var: Düşünmek her zaman doğruyu bulmak anlamına gelmiyor. Bugün en gelişmiş modeller bile, kendinden emin bir ses tonuyla hatalı veya uydurma bilgiler paylaşabiliyor. Finans, sağlık, hukuk ya da eğitim fark etmiyor hatalı bilgi her alanda risk demek. Bu da bizi şu soruya götürüyor: “Yapay zekâ güvenilir olabilir mi?” İşte bu soruya verilen en güçlü yanıtlardan biri ReAct’tir.
2022 yılında Yao, Zhao, Yu ve ekibi tarafından geliştirilen ReAct (Reasoning + Acting), modelleri yalnızca düşünmeye değil, aynı zamanda sorgulamaya, doğrulamaya ve gerektiğinde planını güncellemeye teşvik eden bir yaklaşımdır. ChatGPT’nin çıkışından kısa süre önce yayımlanan bu çalışma, bugün AgentGPT veya AutoGPT gibi otonom sistemlerin temelini oluşturmuştur. ReAct, yapay zekâya “düşünmeden önce bir kontrol et” diyen ilk yaklaşımdır.

Sorun: Düşünen Ama Araştırmayan Modeller
Dil modelleri son birkaç yılda ciddi bir sıçrama yaptı. Artık adım adım mantık yürütebiliyorlar. Fakat hâlâ büyük bir eksikleri var: Gözlem. Model sadece eğitim verisine dayanıyor ve yeni bilgiye ulaşamıyor. "2025 Dünya Kupası’nı kim kazandı?" diye sorduğunuzda eğer verisinde yoksa, tahmin yürütüyor — ve bu hatalı bir yanıtla sonuçlanabiliyor. İşte buna hallüsinasyon diyoruz.
Hallüsinasyonlar yalnızca teknik bir hata değildir. Gerçek dünyada ciddi sonuçlar doğurabilir. Bir hukuk sistemi yanlış karara dayanabilir, bir sağlık sistemi hatalı tedavi önerisi sunabilir, bir finans aracı yanlış analiz yapabilir. Kısacası, bilgiye güven olmazsa yapay zekânın tüm potansiyeli çöker. Bu yüzden, düşünmenin ötesine geçip sorgulamayı öğretmek gerekiyordu. İşte burada ReAct devreye giriyor.

Çözüm: Düşün, Harekete Geç, Gözlemle, Yeniden Düşün
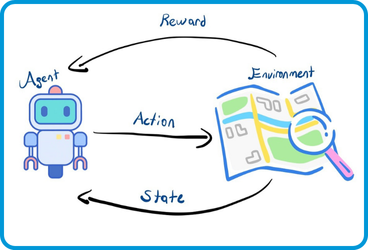
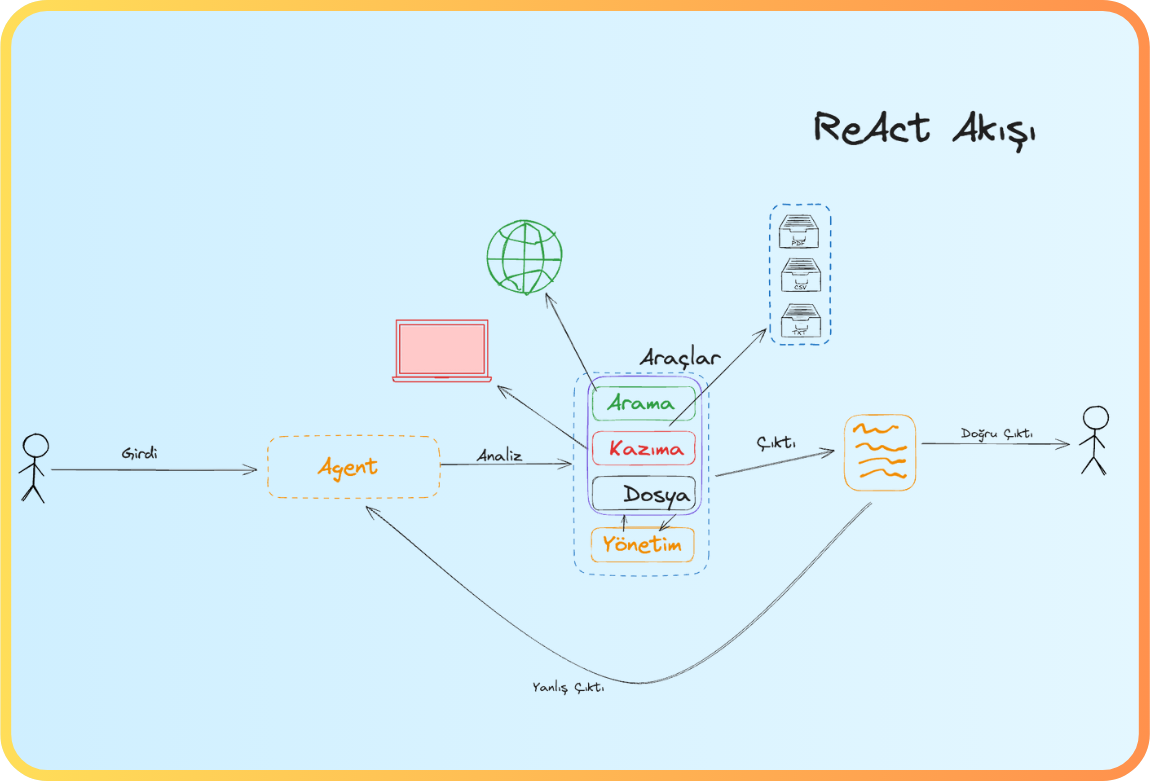
ReAct’in felsefesi basit: Düşünmek yetmez, harekete geçmek gerekir. Model, dış kaynaklara erişebilir, eylem gerçekleştirebilir ve sonuçları gözlemleyip kararını güncelleyebilir.
Kullanıcı Sorusu: Aziz Sancar hangi dalda Oscar aldı?
Eski sistem: "Cevabı biliyorum. Cevap: X.”
ReAct sistemi: "Bilmiyorum, kontrol edeyim."
Eylem: Aziz Sancar hakkında Wikipedia’da arama yap.
Gözlem: “Aziz Sancar, 1946-2025, Türk doktor…”
Sonuç: “Artık doğrulanmış bilgiye sahibim.”
Bu süreç modelin hem düşünmesini hem de eylemde bulunmasını sağlıyor. Artık model yalnızca içeriye kapanmış bir kutu değil aksine dış dünyayla iletişim kurabilen, bilgi doğrulayabilen ve kararını revize edebilen bir unsur haline geliyor. Bu da ona insan benzeri bir öğrenme davranışı kazandırıyor.
Basit bir örnek düşünelim: Bir kullanıcı modelden “Türkiye’de yapay zekâ ile ilgili en son yasal düzenlemeler nelerdir?” diye sorduğunda, klasik sistem tahmin ederdi. ReAct modeli ise bu bilgiyi arar, gözlemler, gerekirse birden fazla kaynağı karşılaştırır ve sonra yanıt üretir. Böylece güvenilirlik katlanarak artar.
Gerçekten İşe Yarıyor mu?
Yao ve ekibinin araştırmaları, ReAct’in yalnızca teoride kalmadığını gösteriyor. Modelin bilgi sorgulama görevlerinde doğruluk oranı %10 ila %20 arasında artmış durumda. Etkileşimli görevlerde, örneğin e-ticaret simülasyonlarında — “100–150 TL aralığında siyah deri laptop çantası bul ve fiyat karşılaştırması yap” gibi — başarı oranı %34’e kadar yükseldiğini belirtiyorlar.
Bu farkın nedeni: ReAct tahmin etmiyor, sorguluyor. Hallüsinasyon oranı azalıyor, güven artıyor. ReAct tabanlı sistemler, kullanıcıya yalnızca cevap vermiyor; aynı zamanda cevabın neden doğru olduğunu da açıklıyor.
Yani ReAct sadece doğruluğu artırmakla kalmıyor, güveni de inşa ediyor. Bu da kullanıcı deneyiminde önemli bir gelişme. Çünkü güven, modern yapay zekânın en zayıf ama en kritik halkası.
Her Gücün Bir Bedeli Vardır
ReAct güçlü, ama elbette kusursuz değil. Her doğruluk adımı bir maliyetle gelir. Dış veri kaynaklarına yapılan sorgular sistemi yavaşlatabilir. Harici API kullanımı, özellikle yüksek trafik altında maliyetli hale gelebilir. Ayrıca, sistemin başarısı kullandığı kaynakların kalitesine bağlıdır — kötü bir veri kaynağı ReAct’in gücünü tersine çevirebilir.
Bir diğer zorluk da gizliliktir. ReAct harici sistemlerle etkileşime geçtiği için, kişisel veya kurumsal verilerin korunması büyük önem taşır. Bu nedenle, sistemin yalnızca güvenilir ve izinli kaynaklarla çalışması gerekir. Ayrıca, bu sistemin doğru entegrasyonu için teknik bilgi, API yönetimi, veri erişimi ve güvenlik politikaları gibi unsurların dikkatle planlanması şarttır.
Ama tüm bu maliyetlere rağmen ReAct, güvenilirliğin kritik olduğu alanlarda büyük avantaj sağlar. Hızdan feragat edip doğruluğa odaklanmak, çoğu kurum için daha sürdürülebilir bir stratejidir. Çünkü kullanıcı güvenini kazanan sistemler, uzun vadede rekabet üstünlüğü sağlar.
Yapay Zeka Artık Sadece Düşünmüyor, Sorguluyor
ReAct, yapay zekânın evriminde sadece bir yöntem değil, bir yaklaşım devrimidir. Model artık sadece düşünmüyor — gözlemliyor, sorguluyor, plan yapıyor, gerekirse kararını değiştiriyor. Tıpkı bir insan gibi, hata yaptığında geri dönüp “Nerede yanlış yaptım?” diyebiliyor.
Bu da bizi geleceğin dünyasına taşıyor: Yapay zekâ yalnızca bilgi üretmeyecek, aynı zamanda onu doğrulayacak, açıklayacak ve sorumluluk alacak. ReAct, bu yeni dönemin temellerini atan sistemdir.
Sonuç olarak ReAct, akıllı sistemleri daha akıllı hale getirmekten öte, onları daha dürüst, daha şeffaf ve daha güvenilir kılar. Çünkü bazen en iyi cevap, hemen verilen değil, doğrulanmış olandır.
Burdan sonra DeepAgent kavramı ile ReAct yaklaşımının gücünü daha iyi anlayacağız.Görüşmek üzere.
Kaynakça
Ana Makale:
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629
İlgili Makaleler:
- Wei, J., et al. (2022). Emergent Abilities of Large Language Models. arXiv:2206.07682
- Brown, T. A., et al. (2020). Language Models are Few-Shot Learners. arXiv:2005.14165
- Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. arXiv:2203.02155
İlginizi Çekebilecek Diğer Blog Yazılarımız
- Finans Dünyasının Yeni Mesai Arkadaşı “Agentic AI” ile Yakınlaşın (10.10.2025)
- Bankacılık ve Yapay Zekâ Kullanımı: Mevcut Durum ve Gelecek (23.10.2025)
- Yazılım Testinin Yapay Zekâ ile İmtihanı (19.08.2025)
- Yapay Zekâ Destekli Kod İyileştirme: SonarQube ve MCP (01.08.2025)
- Asistan Yapay Zekâ Finans Sektörünü Nasıl Dönüştürecek (02.07.2025)
- Yapay Zekânın Gölgelerini Aydınlatan Fener: XAI – Part 1 (31.08.2023)
- Yapay Zekânın Gölgelerini Aydınlatan Fener: XAI – Part 2 (05.09.2023)
- Yazılım Testinde Paradigma Tuzakları: Yapay Zekâ Çağında Kritik Bir Soft Skill (26.08.2025)