Bazen veri tabanında çalıştırdığımız sorguların daha hızlı sonuç dönmesini bekliyoruz. Tabii bu beklentinin yanında bir de bu sorguları çalıştırırken veri tabanını yormak da istemiyoruz. Peki bu mümkün mü?
“Doğru Index kullanımı, hızlandırır” cümlesi ile yazıma başlamak istiyorum.
Veri tabanında INDEX yapısını ve kullanımını bu yazımda 4 ana başlıkta ele alacağım,
Bunlar;
- Index Nedir
- Index Çeşitleri
- Index Nasıl Kullanılır
- Index İçerisinde Kullanılan Fonksiyonlar
Peki nedir bu Index?
Index bir veri tabanının tablolarındaki veriler sorgulandığında daha az veri okuyarak çok daha hızlı bir şekilde veriye ulaşmayı amaçlayan ve işlem sonucunu daha hızlı döndüren yapılardır.
Index'ler, veri alma sorgularının (SELECT deyimi) performansını hızlandırırken, veri yazma sorgularında (INSERT ve UPDATE deyimleri) ek bir adım gerektirdiğinden dolayı bu işlemleri biraz yavaşlatabilir. Ancak, çoğu veri tabanı uygulamasında okuma işlemlerinin yazma işlemlerine göre daha sık gerçekleştiği göz önünde bulundurulursa, index'lerin sağladığı performans artışı genellikle bu küçük kaybın çok ötesine geçer. Bununla birlikte, index'lerin veri içeriği üzerinde herhangi bir etkisi yoktur.
Index’i, bir kitabın içindekiler sayfası, bir kütüphanede aradığınız kitabı bulmak için izlediğiniz yol veya cep telefonunuzdaki rehber olarak düşünebilirsiniz.
Bir bilişim etkinliğine kayıt yaptırdınız ve etkinlik günü yerinizi bulmak istiyorsunuz ama isimlerin yer aldığı doküman karışık olarak hazırlanmış diyelim, kendinizi bulmak için bütün dokümanı taramanız gerekirdi.
Doküman kayıt sırasına göre hazırlanmış olsaydı kayıt numaranızdan arayabilirdiniz (Clustered Index).
Adı soyadına göre sıralı ikinci bir doküman olsaydı yerinizi daha erken bulabilirdiniz (Non-Clustered Index).
Peki, ne zaman Index kullanalım?
Sorgularınız istenenden çok daha geç cevap dönüyorsa.
Sorgularınızda koşul içerisinde sürekli kullanılan bir sütun varsa.
Sorgulanan sütunda çok farklı değerler var ise ve fazla NULL değer içermiyorsa.
Bir veya daha fazla sütun, sıklıkla bir WHERE ifadesiyle bir join işlemi ile birlikte kullanılıyorsa.
Ne zaman Index kullanmak doğru olmaz?
Listede bulunan maddelerin ortak kümesi “sorguda çok sık kullanılan sütunlar” ya da “çok hızlı ulaşılması amaçlanan veriler” için geçerli olmasıdır.
Küçük tablolarda index’ler kullanılmamalıdır.
Sık sık, büyük toplu güncellemeler veya ekleme işlemleri yapılan tablolarda kullanılmamalıdırlar.
Çok sayıda NULL değer içeren sütunlarda index’ler kullanılmamalıdır.
Sıklıkla manipüle edilen sütunlar indekslenmemelidir.
Ayrıntılı bilgi için: SQL Server and Azure SQL index architecture and design guide
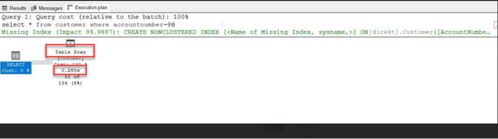
Örneğin; 1414273 satır veri olan bir tabloda SELECT deyimi çalıştırıldığında;

Tabloya herhangi bir Index tanımı yapılmadığında veri table scan yaparak getirilir.
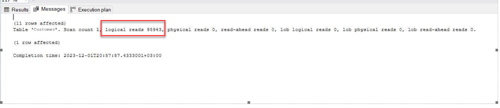
Table scan ile okunan sayfa sayısı 95943 (Şekil 2), yürütme planındaki sürenin ise 0.285 s (Şekil 3) olduğu görünmektedir.
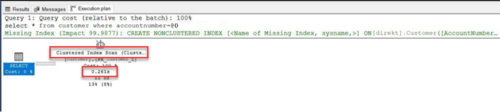
Clustered Index oluşturulduğunda veriyi clustered index üzerinden getirir.
Clustered Index ile okunan sayfa sayısı 88530 (Şekil 4), yürütme planındaki sürenin ise 0.261 s (Şekil 5) olduğu görünmektedir.

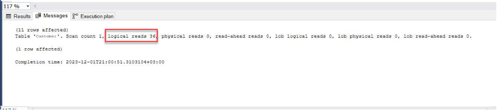
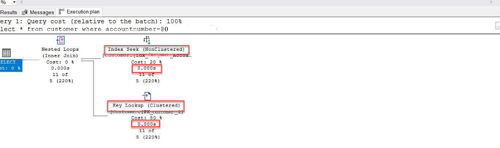
Non-clustered index tanımladığında veriyi getirmek için hem clustered hem de non-clustered index kullanır.
Non-clustered index ile okunan sayfa sayısı 36 (Şekil 6), yürütme planındaki sürenin ise 0.000s (Şekil 7) olduğu görünmektedir.
Index Çeşitleri
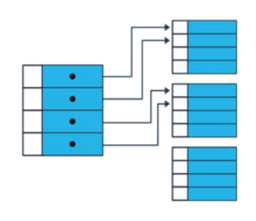
1) Clustered Index
a. Tablonun verilerini fiziksel olarak sıralar.
b. Bir tabloda bir tane clustered index olabilir.
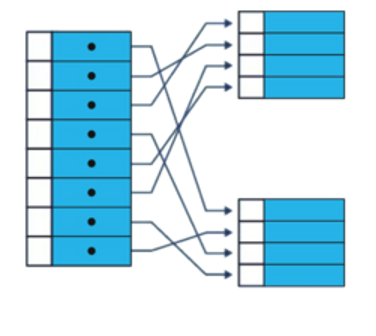
2) Non-Clustered Index
a. Bir tabloda “n” tane non-clustered index olabilir.
b. Non-clustered index’ler indekste belirtilen kolonlar ile oluşturulan ağaç yapılarıdır ve ana tablonun satır referansını bulundururlar. Kitap sonlarında bulunan index’ler bunlara en iyi örnektir. İlgili verinin hangi sayfada olduğunu belirtip, kolayca ona konumlanmamızı sağlar.
c. Index’te ınclude içerisine eklenen alanlar ile sıralama yapılmaz. Index’e erişildiğinde tekrar tabloya gitmemek için include (lookup) alanlar kullanılır.
3) Unique Index
a. Bir tablo indeksleme alanı olarak seçilen sütundaki verilerin tekrarlanması istenmiyorsa, indeksleme yapılırken, CREATE INDEX komutu içinde UNIQUE sözcüğü kullanılmalıdır.
b. Ekran üzerinden yapılıyorsa UNIQUE özelliği seçilmelidir.
4) Filtered Index
a. Filtered index non-clustered index içerisine filtre eklenmesi ile oluşur.
5) Composite Index
a. Index oluşturulurken birden fazla kolon index’e eklendiğinde composite index adını almaktadır.
b. Birden fazla parametre varsa bu composite index olur.
6) Covered Index
a. Orijinal tabloya ihtiyaç olmadan bir index’e konumlanıp değerleri bulmak için covered index kullanılır.
7) Column Store Index
a. Veri ambarı raporlama / sıkıştırma ve kolon bazlı sıralama / veriyi analitik sıralama işlemlerinde kullanılır.
8) Full-Text Index
a. 10.000 kelimelik metin içinde bir kelime aranırken bu metinleri kelimeler halinde sıralayan yapılara full-text index denir.
b. Like ile aramak yerine full-text index’e ait özel fonksiyonlar olan CONTAINS gibi fonksiyonlar kullanılabilir.
MSSQL’de Index Oluşturma
Index ekleme, silme ve güncelleme işlemleri 2 şekilde yapılabilir:
Sorgu yolu ile;
CREATE fonksiyonu kullanılarak yeni index oluşturulabilir.
CREATE INDEX index_adi
ON tablo_adi (sutun1, sutun2, …);
USE [ornek
GO
SET ANSI_PADDING ON
GO
CREATE NONCLUSTERED INDEX [IX_customer_accountnumber] ON [Customer]
(
[Accountnumber] ASC,
)
WITH
(PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
DROP_EXISTING = OFF,
ONLINE = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON,
FILLFACTOR = 95) ON [db]
GO
DROP INDEX index_adi
ON tablo_adi (sutun1,sutun2,…);
USE [BOA]
GO
DROP INDEX [IX_customer_accountnumber] ON [customer]
GO
SQL üzerinden,
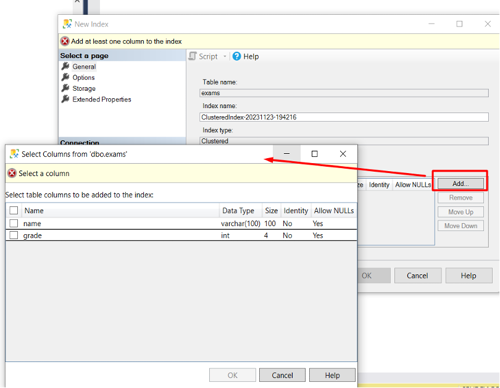
Index oluşturulacak tablo içerisinden Indexes’e sağ tıklayıp yeni Index seçeneği ile oluşturulmak istenen Index tipi seçilir.

Index seçildikten sonra New Index sayfasındaki bilgiler otomatik olarak dolacaktır. Index Name ismi değiştirilebilir, Index’in aynı zamanda UNIQUE olması isteniyorsa bu ekrandan seçilebilir.

Ekle butonu ile Index’te kullanmak istediğiniz tablo alanlarını ekleyebilirsiniz.

Index İçerisinde Kullanılan Fonksiyonlar
Pad_Index
- Index oluşturma sırasında FillFactor tarafından belirtilen boş alan yüzdesini dizin orta seviye sayfalarına uygulamak için kullanılır.
- ON/OFF değerlerini alır.
Fillfactor
- Index oluşturma sırasında SQL Server motorunun her dizin sayfasının yaprak düzeyinde bırakacağı boş alan yüzdesini ayarlamak için kullanılır.
- FillFactor, 0 ila 100 arasında bir tamsayı değeri olmalıdır.
Sort_In_Tempdb
- Index oluşturma sırasında oluşturulan ara sıralama sonuçlarının tempdb'de yapılıp yapılmayacağını belirtir.
- ON/OFF değerlerini alır.
Ignore_Dup_Key
- Benzersiz dizine yinelenen anahtar değerleri eklendiğinde bir hata mesajının gösterilip gösterilmeyeceğini belirtir.
Statistics_Norecompute
- Eski index istatistiklerinin otomatik olarak yeniden hesaplanıp hesaplanmayacağını belirler.
- İstatistikleri güncelleştirme işlemi yoğun kaynak kullanımı gerektirebilir. Çok büyük bir tablonuz varsa ve değişiklikler sık yapılıyorsa, istatistiklerin otomatik olarak güncelleştirilmesi performans sorunlarına neden olabilir.
Drop_Existing
- Adlandırılmış mevcut index’in bırakılıp yeniden oluşturulacağını belirtir.
- ON/OFF değerlerini alır.
Online
- Index oluşturma işlemi sırasında temel tablolara sorgular ve veri değişiklikleri için erişilip erişilemeyeceğini belirtir.
- Index oluştururken, diğer DML işlemlerinin etkilenmemesi için WITH(ONLINE=ON) parametresi ile create/alter edilmelidir.
Allow_Row_Locks
- Satır kilitlerinin index verilerine erişmesine izin verilip verilmeyeceğini belirler.
- ON/OFF değerlerini alır.
Allow_Page_Locks
- Sayfa kilitlerinin index verilerine erişmesine izin verilip verilmeyeceğini belirler.
- ON/OFF değerlerini alır.
Maxdop
- Index oluşturma işleminin paralel planda yürütülmesinde kullanılan maksimum işlemci sayısını sınırlamak için kullanılır.
Data_Compression
- Belirtilen index, bölüm numarası veya bölüm aralığı için NONE, ROW ve PAGE değerleriyle veri sıkıştırma düzeyini belirtir.
Bu yazıda, veritabanı performansını artırmak amacıyla index'lerin ne olduğu, çeşitleri, nasıl kullanıldığı ve içerisinde kullanılan fonksiyonları detaylı bir şekilde ele aldık. Index'lerin, sorguların hızını nasıl etkilediğini, veri türlerine ve ihtiyaçlara göre hangi çeşitlerin uygun olduğunu ve veritabanı performansını nasıl optimize edebileceğinizi tartıştık. Ayrıca, index'lerin içerisinde kullanılan çeşitli fonksiyonlar hakkında bilgi vererek index'lerin kullanımını nasıl daha etkili hale getirebileceğinizi açıkladık. Veritabanı tasarımını ve performansını optimize etmek, dengeli ve bilinçli bir yaklaşım gerektirir. Daha fazla bilgi almak veya bu konuda derinlemesine bir inceleme yapmak isterseniz, kaynakça bölümündeki bağlantılara göz atabilirsiniz.
Katkıları ve destekleri için Ahmet Fatih Aktaş’a teşekkür ederim.
Kaynakça ve Faydalı Bağlantılar
- https://learn.microsoft.com/en-us/sql/relational-databases/indexes/indexes?view=sql-server-ver16 (Erişim Tarihi: 01.12.2023)
- https://www.youtube.com/watch?v=wWf1fUQ9wSc&themeRefresh=1 (Erişim Tarihi: 01.12.2023)
- https://blog.sqlauthority.com/2023/09/08/sql-server-the-comprehensive-guide-to-statistics_norecompute/#:~:text=The%20STATISTICS_NORECOMPUTE%20option%2C%20used%20within,the%20statistics%20for%20that%20index. (Erişim Tarihi: 01.12.2023)
- https://sqlperformance.com/2019/04/sql-performance/ignore_dup_key-slower-clustered-indexes (Erişim Tarihi: 01.12.2023)
- https://learn.microsoft.com/en-us/sql/relational-databases/sql-server-index-design-guide?view=sql-server-ver16(Erişim Tarihi: 01.12.2023)