Açıklanabilir AI nedir? Kavramlar ve Örnekler
Açıklanabilir Yapay Zekâ (XAI), yapay zekâ sistemlerinin karar verme süreçlerini insanların anlayabileceği şekilde açıklamaya yardımcı olan bir kavramdır. Yapay zekânın yaygınlaşması ve gelecekteki olası sonuçlarının öngörülememesi endişesiyle ortaya çıkmıştır. Basitçe söylemek gerekirse, XAI, insanlar tarafından anlaşılabilen yapay zekâ biçimidir. İnsanlara, kararların makineler tarafından nasıl alındığını açıklama yeteneği sağlar. Bu, insanların bilgilerinin izinsiz kullanıldığı hissinden kurtulmalarına ve yapay zekâ sistemlerine güvenmelerine yardımcı olur. XAI, yapay zekâ sistemlerinin şeffaflığını, güvenilirliğini ve hesap verebilirliğini artırır. Ayrıca, makine öğrenimi modellerinin verdiği belirli tahminlerin veya kararların mantığını anlamak için de kullanılabilir. Örneğin, bir yapay zekâ modeli, bir hastalığın teşhisini yapmak için kullanıldığında, XAI, bu teşhisin neden bu şekilde yapıldığını ve hangi özelliklerin belirleyici olduğunu açıklayabilir. Bu blog yazısında, açıklanabilir AI kavramlarını anlatacağız ve günümüzde nasıl kullanıldığına dair örnekler vereceğiz.
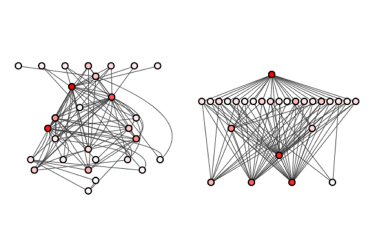
XAI, yapay zekâ sistemlerinin karar verme süreçlerinin anlaşılmasını ve güvenilirliğinin artırılmasını sağlayan bir kavramdır. XAI teknikleri, yapay zekâ sistemlerinin insanlar tarafından anlaşılabilir hale getirilmesine yardımcı olur ve bu sayede insanlar, bu sistemlere daha fazla güvenebilirler. Aşağıda Şekil 1, açıklanabilirliğin devreye girdiği iş akışını göstermektedir.
XAI, doğrusal regresyon, rastgele orman, karar ağaçları, sinir ağı algoritmalardan herhangi biri kullanılarak eğitilen bir makine öğrenimi modelinin kararının arkasındaki mantığı açıklamaya yardımcı olur.
Örneğin (Lime Package — Lime 0.1 Documentation, n.d.), LIME (Local Interpretable Model-Agnostic Explanations) ve Shapley Additive Explanations (SHAP), bir makine öğrenimi modeli tarafından verilen kararları yerel yorumlar kullanarak açıklamaya olanak tanıyan açıklanabilirlik araçlarıdır.
Açıklanabilir Yapay Zekâ (XAI)’nın Faydaları ve Zorlukları

XAI, etik yapay zekânın önemli bir yönünü oluşturur. Açıklanabilir AI kullanmanın temel faydaları şunlardır:
- Hesap verebilirliği içeren kullanım durumlarında XAI istenmektedir. Örneğin XAI, bir kaza durumunda kararlarını açıklayabilen otonom araçların kurulmasına yardımcı olabilir.
- XAI, hassas bilgiler veya bunlarla ilişkili veriler içeren senaryoların olduğu (ör. sağlık hizmetleri) adalet ve şeffaflık içeren durumlar için kritik öneme sahiptir.
- İnsanlar ve makineler arasındaki güvenin atmasını sağlar.
- Model karar verme sürecinde daha yüksek görünürlük ve şeffaflığa yardımcı olur.
Açıklanabilir AI ile ilgili bazı zorluklar şunlardır:
- Açıklanabilir AI, nispeten yeni bir araştırma alanıdır ve bugün hala açıklanabilir modellerin sunduğu birçok aktif zorluk vardır. XAI sistemleri, açıklanamayan modellere veya kara kutu modellerine kıyasla daha düşük performansa sahip olma eğilimindedir.
- XAI’daki en önemli zorluklardan biri hem doğru hem de anlaşılır açıklamaların nasıl üretileceğidir.
- XAI modellerinin geliştirilmesinde karşılaşılan diğer önemli bir zorluk, bu modellerin açıklanamayan yapay zekâ modellerine kıyasla daha zor eğitilebilir ve daha az doğru olabilmesidir. Bu durumun sebebi, açıklanabilir modellerin doğruluğu ile yorumlanabilirliği arasında bir denge kurması gerektiğinden dolayı, bazı özellikler doğruluğu arttırabilir ancak modeli daha karmaşık ve açıklanması zor hale getirebilir.
- Diğer bir zorluk da XAI sistemleri genellikle karmaşık ve yüksek boyutlu veri setleri üzerinde çalışırlar. Bu nedenle, sistemlerin kararlarını ve sonuçlarını yorumlamak, sisteme girdi olarak verilen verilerin ne anlama geldiğini ve nasıl yorumlanması gerektiğini anlamak için insanların sisteme müdahale etmesi gerekebilir. Bu durum uygulamanın tamamlanmasını daha zor hale getirebilir.
Açıklanabilir Yapay Zekâ (XAI) da LIME Kullanımı
LIME
LIME (Local Interpretable Model-Agnostic Explanations): Modelden bağımsız olan bu yöntem, herhangi bir makine öğrenimi modelini aydınlatmaya ve tahminlerini ayrı ayrı anlaşılır hale getirmeye yardımcı olur. Yöntem, belirli bir tek örnek için tahminin nasıl değiştiğini anlayarak algoritmayı açıklar ve bu nedenle yerel açıklamalar için uygundur.
Herhangi bir sınıflandırıcı veya regresörün tahminlerini yerel olarak yorumlanabilir bir modelle yaklaştırarak doğru bir şekilde açıklayabilen bir algoritmadır. Özellik değerlerini değiştirerek tek bir veri örneğini değiştirir ve sonuçta çıktı üzerindeki etkiyi gözlemler. Her veri örneğinden gelen tahminleri açıklamak için bir “açıklayıcı” rolünü yerine getirir. LIME çıktısı, her bir özelliğin tek bir örneklem için bir tahmine olan katkısını temsil eden bir dizi açıklama olup, bir yerel yorumlanabilirlik biçimidir.
LIME ile yorumlanabilir modeller, örneğin, iyi bir yerel yaklaşım sağlamak için orijinal modelin küçük düzensizlikleri (bu düzensizlikler; gürültü ekleme, sözcükleri çıkarma, görüntünün parçalarını gizleme olabilir) üzerine eğitilmiş doğrusal regresyon veya karar ağaçları olabilir.
LIME nasıl çalışır?
Genel olarak, bir tahmin modeli ve bir test örneği verildiğinde, LIME aşağıdaki adımları gerçekleştirir:
Sampling kullanarak temsili veri kümesi oluşturma: LIME hedef veri kümesi için local olarak doğru açıklamalar sağlar. Varsayılan ayarlarda, normal dağılama sahip özellik vektörünün 5000 (konfigure edilebilir) adet örneğini üretir. Daha sonra kararlarını açıklamaya çalıştığı tahmin modelini kullanarak bu 5000 örnek için hedef değişkeni elde eder.
Train veri kümesinden özellik seçimi: train veri kümesini elde ettikten sonra, orijinal örneğe/gözlemlere ne kadar yakın olduklarına göre her satırı ağırlıklandırır. Ardından, en önemli özellikleri elde etmek için Lasso (İstatistik ve makine öğreniminde kement, elde edilen istatistiksel modelin tahmin doğruluğunu ve yorumlanabilirliğini geliştirmek için hem değişken seçimi hem de düzenlileştirme gerçekleştiren bir regresyon analizi yöntemidir.) gibi bir özellik seçme tekniği kullanır.
LIME ayrıca, yalnızca elde edilen özellikleri kullanan örnekler üzerinde bir Ridge Regresyon (Ridge regresyon, bağımsız değişkenlerin yüksek oranda ilişkili olduğu senaryolarda çoklu regresyon modellerinin katsayılarını tahmin etme yöntemidir) modeli kullanır. Çıktı tahmini, teorik olarak orijinal tahmin modelinin bir çıktısına büyüklük olarak benzer olmalıdır. Bu, elde edilen bu özelliklerin alaka düzeyini ve önemini vurgulamak için yapılır.
LIME Kurulumu
Kurulum kısmına gelecek olursak, LIME’ı Python’a kurmak için pip veya conda kullanabiliriz.

Veri Kümesi Açıklaması:
LIME şu anki haliyle sadece aşağıdaki tipteki veri kümeleri için açıklama yapabilmektedir:
Tablolu veri kümeleri (lime.lime_tabular.LimeTabularExplainer): örn: Regresyon, sınıflandırma veri kümeleri.
Görüntüyle ilgili veri kümeleri (lime.lime_image.LimeImageExplainer)
Metinle ilgili veri kümeleri (lime.lime_text.LimeTextExplainer)
Kullanılan Tahmin Modeli:
LIME doğası gereği modelden bağımsız olduğundan, kendisine atılan hemen hemen her modeli işleyebilir.
LIME Kullanımı İçin Örnek Bir Uygulama
LimeTabularExplainer:
Analiz için bir tablo veri seti kullanılacaksa bu tür veri kümelerini açıklamak için LIME’ın API’si LimeTabularExplainer’ı kullanılır.
Syntax: lime.lime_tabular. LimeTabularExplainer(training_data, mode, feature_names, verbose)
Parameters:
- training_data – 2d array consisting of the training dataset
- mode – Depends on the problem; “classification” or “regression”
- feature_names – list of titles corresponding to the columns in the training dataset.
If not mentioned, it uses the column indices. - verbose – if true, print local prediction values from the regression model trained on the samples using only the obtained features
Belirli bir test örneğini açıklamak için varsayılan ayarlarda tanımlanmış açıklayıcı nesneden bir yöntem kullanacağız.
Syntax: explain_instance(data_row, predict_fn, num_features=10, num_samples=5000)
Parameters:
- data_row – 1d array containing values corresponding to the test sample being explained
- predict_fn – Prediction function used by the prediction model
- num_features – maximum number of features present in explanation
- num_samples – size of the neighborhood to learn the linear model
Yukarıda kısa olarak tek bir fonksiyonu ele aldık. LIME paketinin tüm fonksiyonlarını (Lime Package — Lime 0.1 Documentation, n.d.) kaynağından bulabilirsiniz bulabilirsiniz.
Workflow
1-Veri ön işleme
2-Veri kümesi üzerinde Ekstra ağaç regresörü eğitimi
3-Belirli bir test örneği için açıklamaların elde edilmesi
Analiz
1. Scikit-learn yardımcı programından verileri çıkarma

Boston’da ev fiyatlarını belirleyen etkenleri barındıran data seti;

2. Özellik matrisi x’i, hedef değişkeni y’yi çıkarma ve bir train-test seti ayırması yapma


3. Tahmin modelini başlatma ve (X_train, y_train) üzerinde eğitme


4. Explainer object’in kurulması

5. allow_instance () yöntemini çağırarak açıklama elde etme
Tahmin modelinin i‘inci test vektörü için; verdiği tahminin arkasındaki mantığı araştırmak istediğimizi varsayalım. Ayrıca, buna sebep veren en önemli k özelliği görselleştirmek istediğimizi varsayalım, i & k’nin iki kombinasyonu isteğe bağlı olarak değiştirelebilirnir.
5.1. i=10, k=5 için kararların açıklanması Temel olarak LIME’dan, söz konusu modelin tahminine katkıda bulunan ilk 5 (k) özelliği göstererek 10. (i) test vektörü için tahminlerin arkasındaki kararları açıklamasını istiyoruz.


Çıktıları yorumlama;
Öncelikle, üç değer görüyoruz:
Intercept: Yukarıdaki lineer modelin tahmini için verilen test vektörü için sabit kısmıdır. İntercept, lineer modelin kesim noktasını gösterir ve tahmin sonucunu etkileyen sabit bir değerdir.
Right: Verilen test vektörü için tahmin modelimiz (bu durumda bir ekstra ağaç regresörü) tarafından verilen tahmini gösterir.
Prediction_local: LIME tarafından elde edilen en iyi k özellikleri kullanarak, bozulmuş örnekler üzerinde eğitilmiş bir lineer model tarafından üretilen değerdir. Bu değer, test vektörü için tahmin edilen hedef değişkenidir. Özetle, Right değeri, tahmin modelinin test vektörü için tahmini değeridir. Prediction_local ise LIME tarafından seçilen en önemli özellikleri kullanarak elde edilen yeni bir tahmin değeridir. Intercept ise bu yeni tahmin değerinin lineer model tarafından hesaplanırken kullanılan kesim noktasını ifade eder.

Görselleştirmelere gelince, sırasıyla negatif ve pozitif çağrışımları gösteren mavi ve turuncu renkleri görebiliriz. Ayrıca bu sample için en önemli 5 özellik sıralamasını grafikten görebiliriz.
Yukarıdaki Şekil 2 de belirtilen sonuçları yorumlamak için, verilen vektör tarafından gösterilen evin nispeten düşük fiyat değerinin (solda bir çubukla gösterilen) aşağıdaki sosyo-ekonomik nedenlere bağlanabileceği sonucuna varabiliriz:
LSTAT değerinin yüksek olması, bir toplumun eğitim ve nüfus açısından düşük durumunu göstermektedir.
PTRATIO’nun yüksek değeri, öğretmen başına düşen öğrenci sayısının yüksek değerini gösterir.
INDUS’un yüksek değeri, kasaba başına perakende dışı iş alanlarının yüksek oranını gösterir.
Düşük RAD değeri, radyal otoyollara daha az erişilebilirlik endeksi olduğunu gösterir.
RM’nin düşük değeri, konut başına daha az oda miktarını gösterir.
Nispeten karmaşık bir tahmin modeli (bir ekstra ağaç regresörü) tarafından alınan kararları yorumlanabilir ve anlamlı bir şekilde ilişkilendirmenin ne kadar kolay hale geldiğini görebiliriz. Bu alıştırmayı bir test vektörü üzerinde daha deneyelim.
5.2. i=47, k=5 için kararların açıklanması Burada yine LIME’den, söz konusu modelin tahminine katkıda bulunan ilk 5 özelliği göstererek 47. test vektörü için tahminlerin arkasındaki kararları açıklamasını istiyoruz.



Bu örnek için de en önemli 5 özellik sıralamasını Şekil 3 ten görebiliriz.
Görselleştirmelerden, verilen vektör tarafından gösterilen evin nispeten daha yüksek fiyat değerinin (solda bir çubukla gösterilen) aşağıdaki sosyo-ekonomik nedenlere bağlanabileceği sonucuna varabiliriz:
RM değerinin yüksek olması, konut başına düşen oda sayısının yüksek olduğunu gösterir.
LSTAT’ın düşük değeri, bir toplumun nüfus, eğitim ve istihdam edilebilirlik açısından büyük durumunu gösterir.
TAX değerinin düşük olması, mülkün düşük vergi oranını gösterir.
PTRATIO’nun düşük değeri, öğretmen başına düşen öğrenci sayısının iyi olduğunu gösterir.
Kuruluşun yeniliğini gösteren AGE değerinin düşük olması INDUS’un ortalama değeri, cemiyete yakın perakende dışı satış sayısının azlığının, evin değerini bir nebze olsun düşürdüğünü göstermektedir.
Sonuç olarak, XAI genellikle karmaşık yapay zekâ modellerinin iç işleyişini ve kararlarını insanlar tarafından anlaşılabilir bir şekilde açıklama ve insanların yapay zekâ modellerine olan güvenilirliğini arttırma amacı taşıdığına değinmiştik. Verdiğimiz LIME kütüphanesi ile Boston’da ev fiyatlarını belirleyen etkenleri anlamak için kurulan modelde ilk olarak, açıklanabilirlik sağlamak için açıklamaların yapılacağı bir girdi örneği belirledik. Seçilen örnek etrafında rastgele değişiklikler yaparak yeni veri örnekleri oluşturduk. Bu yeni örnekler üzerindeki model çıktılarını hesapladık, modelin tepkisini anlamamıza yardımcı olacak bir veri kümesi oluşturduk. Oluşturulan veri kümesi üzerinde basit bir açıklanabilir model eğittik. Bu modelin, seçilen etiketi (evler pahalı mı, ucuz mu?) üzerindeki etkisini belirlemesini kullanarak, özellikleri sıralayarak ve özelliklerin ne derece etki yaptığını gözlemleyerek açıklama sağladık. LIME, bu yöntemi kullanarak karmaşık yapay zekâ modellerinin kararlarını daha anlaşılır hale getirmeyi amaçlar. Özellikle yüksek boyutlu verilerde ve derin öğrenme modellerinde etkilidir. Bu sayede, modelin hangi özelliklerin ve hangi bölgelerin kararlar üzerinde daha fazla etkili olduğunu anlayabilir ve güvenilirlik ve hesaplanabilirlik açısından değerli bilgiler elde edebilirsiniz.
Kaynaklar
- Kumar, A. (2022, March 28). What is Explainable AI? Concepts & Examples – Data Analytics. Data Analytics. https://vitalflux.com/what-is-explainable-ai-concepts-examples/#Benefits_Challenges_of_Explainable_AI
- lime package — lime 0.1 documentation. (n.d.). https://lime-ml.readthedocs.io/en/latest/lime.html
- Yapay Zeka’ya Güvenebilir miyim? — Explainable AI. (2021, December 1). Mehmet Emin Eker. https://www.mehmetemineker.com/yapay-zekaya-guvenebilir-miyim-explainable-ai/
- GeeksforGeeks. (2023). Explainable AI XAI Using LIME. GeeksforGeeks. https://www.geeksforgeeks.org/introduction-to-explainable-aixai-using-lime/
- Papastratis, I. (2021, March 4). Explainable AI (XAI): A survey of recents methods, applications and frameworks | AI Summer. AI Summer. https://theaisummer.com/xai/
- Meena, P. (2022). Demystifying Model Interpretation using ELI5. Analytics Vidhya. https://www.analyticsvidhya.com/blog/2020/11/demystifying-model-interpretation-using-eli5/
- Trevisan, V. (2022, July 5). Using SHAP Values to Explain How Your Machine Learning Model Works. Medium. https://towardsdatascience.com/using-shap-values-to-explain-how-your-machine-learning-model-works-732b3f40e137