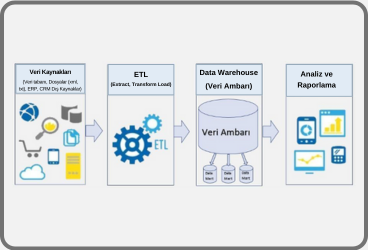
Finansal hizmet sunan kurumlarda büyük ölçekteki veriler arasındaki ilişkilerin incelenebilmesi, tarihsel bağlantıların ortaya çıkarılması ve bunların gerçek zamanlı olarak yapılabilmesi çeşitli iş ihtiyaçları için kaçınılmaz olmaktadır. Bu tarz sistemlere en iyi örneklerden biri olan fraud tespit sistemleri finansal dolandırıcılık vakalarını önlemeyi hedefleyen gerçek zamanlı karar alma mekanizmalarıdır. Bu sistemler finansal işlemler gerçekleşirken, eş zamanlı olarak çalıştırılan çeşitli kurallar ve/veya makine öğrenmesi yöntemleri gibi yöntemler ile işlemlerin kontrol edilmesini ve önleyici tedbirlerin anlık olarak alınabilmesini sağlamaktadır. Büyük miktarda işlem verisi akan bir ortamda çok hızlı yanıt verebilme yeteneğine sahip olması beklenen bu sistemlerin tasarımında en kritik noktalardan biri, verilerin nasıl modelleneceğine karar vermektir.
Bu yazıda, Kuveyt Türk Katılım Bankası’nda aktif olarak kullanılan ve günlük 2,5 milyona yakın işlemi inceleyerek karar üreten fraud tespit ürünümüzü tasarlarken, ilişkisel veri tabanı sisteminden çıkmaya nasıl karar verdiğimizi, sonrasında artıları ve eksileriyle nelerle karşılaştığımızı paylaşacağım. Bunu anlatırken, RDMS üzerinde çalıştırdığımız sistemin avantajı ve dezavantajlarına da değinmiş olacağız.
Veri Tabanı Modelleri
Uygulamalar için veri depolamak ve yönetmek için temelde iki farklı veri tabanı modeli bulunmaktadır. İlişkisel (relational) ve ilişkisel olmayan (non-relational). İlişkisel olmayanların da kendi içinde farklı çeşitleri mevcuttur, bunlara da özetle değinelim.
İlişkisel Veri Tabanı Yönetim Sistemleri (RDMS) :
1970'li yıllarda Edgar Frank Codd tarafından önerilen ve veriyi satır ve sütunlardan oluşan tablolar şeklinde modelleyen sistemlerdir. Birçok sistemde uygun model olarak görülmekte ve günümüzde hala yaygın olarak kullanılmaktadır.


RDMS ne gibi avantajlar sunuyor?
-
ACID desteği ile veri tabanı operasyonlarının daha güvenli bir şekilde yapılması
-
Veri yapısının kolay anlaşılabilir olması,
-
Veri bütünlüğü, veri standardizasyonu ve tutarlılığını garanti edilmesi
-
Normalizasyon ile tekrarlı verileri azaltarak veri boyutunu ve disk maliyetlerinin azaltılması,
-
Uzun zamandır kullanılması sebebiyle araç gereç ve yöntemlerin standartlaşmış olması,
-
Çoğu kişinin aşina olduğu sorgu dilleri ile raporlama ve sorgulamaların basit bir şekilde yapılabilmesi
İlişkisel veri tabanı yönetim sistemlerinin yukarıda maddeler halinde saydıklarımız gibi birçok avantajı bulunmaktadır.
Daha katı, kuralları önceden belirlenmiş, uzunlukları ve tipleri belli olan tabular yapıda veri modeli oluşturmak çoğu büyük ölçekli uygulama için uygun olabilir. (Bankacılık sistemleri gibi). Bu tarz sistemlerde veri mimarisinin kontrollü hale getirilebildiği daha denetlenebilir ve hata yapmayı azaltan, standartlara uygun yapılara ihtiyaç bulunmaktadır.
Fakat esnek bir veri modeli ile çalışmayı gerektiren ve değişime hızlı adapte olması gereken uygulamalar için bu veri tabanı modeli dezavantajlı durumlar oluşturabilmektedir. Ayrıca veri boyutu veri boyutu ve karmaşıklığı arttıkça dikey ölçeklenebilirlik sebebiyle performans noktasında da dezavantajlar yaşanabilmekte olup, sunuculara daha fazla işlemci ve ram ekleme şeklinde maliyetler ortaya çıkarabilmektedir. Bu maliyetler göze alınsa bile bu sefer de donanımsal limitler karşımıza çıkabilmektedir.
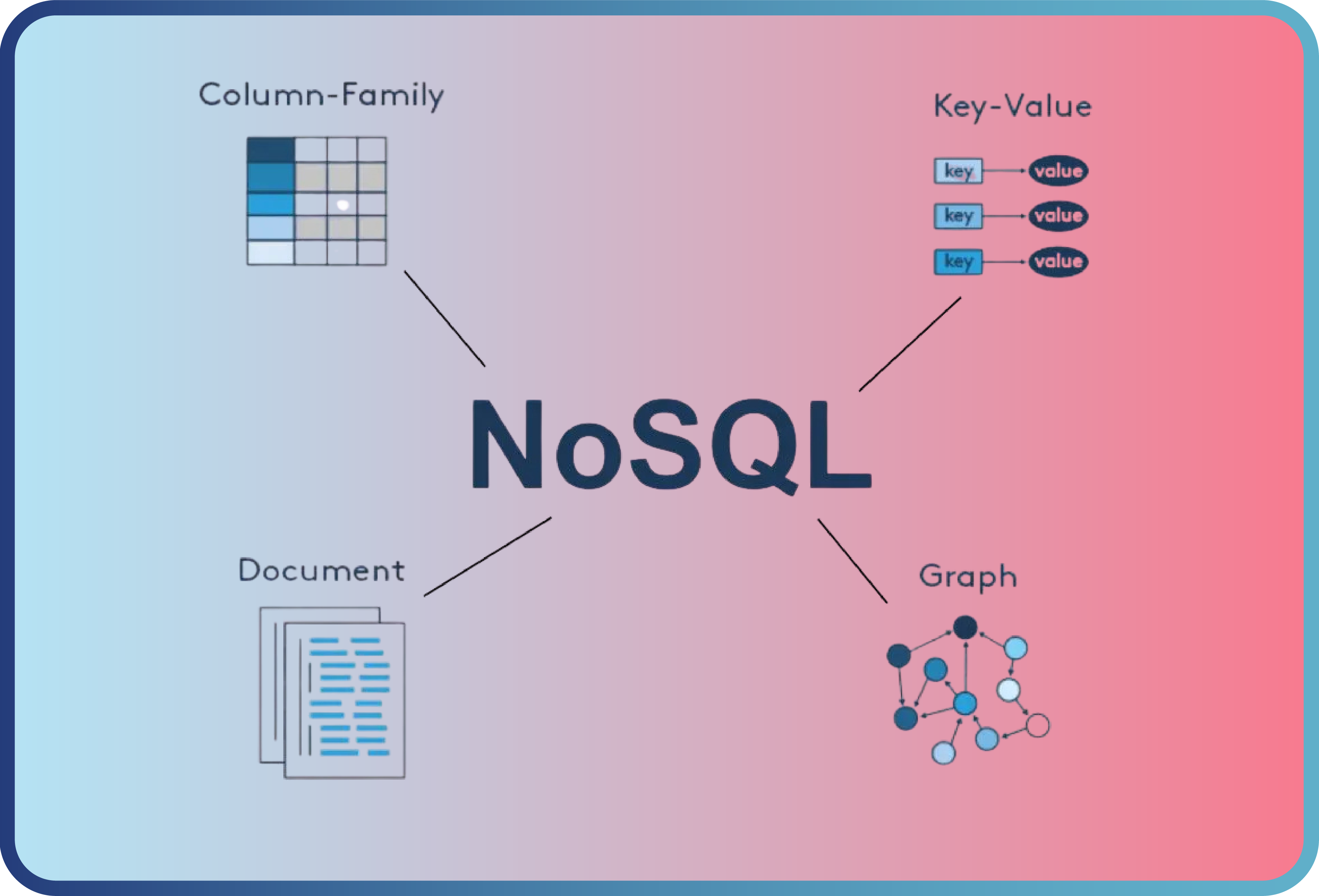
İlişkisel Olmayan (NoSQL) Veri Tabanı Sistemleri
NoSQL veri tabanları, verilerin esnek ve ölçeklenebilir bir şekilde saklanmasını sağlayan veri tabanı türleridir. Geleneksel ilişkisel olanların aksine, NoSQL veri tabanları sabit bir şema gerektirmez ve genellikle büyük veri kümeleriyle çalışmak için optimize edilmiştir.
Günümüzde büyük veri olgusunun ortaya çıkması ve ilgili teknolojilerle birlikte NoSQL veri tabanlarının popülerlik kazanmış olduğunu görmekteyiz. Tabi burada da farklı alternatifler bulunmaktadır. Document-Oriented, Key-Value, Wide-Column, Graph vs. gibi çeşitleri bulunmaktadır. Her biri farklı türdeki ihtiyaçlara çözüm üretiyor.

Bu farklı türlerin özelliklerine kısaca değinirsek:
-
Document store (belge tabanlı veri deposu), verileri belge odaklı bir modelde saklayan bir veri tabanı türüdür. Her kayıt ve ilişkili veriler tek bir belge içinde saklanabilir. Bu belgeler genellikle JSON veya XML formatında olabilir.
-
Graph store (graf tabanlı veri deposu), verileri düğümler (nodes), kenarlar (edges) ve özellikler (properties) kullanarak saklayan bir veri tabanı türüdür. Düğümler nesneleri, kenarlar ise düğümler arasındaki ilişkileri temsil eder. Bu tür bir veritabanı ilişkilerini hızlı bir şekilde sorgulama ve görselleştirme imkânı sağlar.
-
Wide column store (geniş sütun tabanlı veri deposu), verileri sütun aileleri (column families) formatında saklayan bir NoSQL veri tabanı türüdür. Her sütun ailesi, ilişkili verilerin bir grubunu temsil eder ve her satır benzersiz bir anahtara sahiptir.
-
Key-value store (anahtar-değer tabanlı veri deposu), verileri anahtar-değer çiftleri olarak saklayan bir NoSQL veri tabanı türüdür. Her anahtar, benzersiz bir tanımlayıcıdır ve ilişkili değeri almak için kullanılır. Bu yapı, hız ve ölçeklenebilirliğin kritik olduğu senaryolar için idealdir. Key-value store veri tabanları, genellikle hash tabloları veya benzeri veri yapıları kullanır. Tablo 1.0’da hangi kategoride hangi veritabanı çözümlerinin yer aldığı gösterilmiştir.

Tablo 1.0 : Türlerine Göre NoSQL Veritabanı Çözümleri
İlişkisel Veritabanı Sisteminin Zayıf Kaldığı Noktalar ve Uygulamızın İhtiyaçları
Geliştirmiş olduğumuz sistemde, aşağıda maddeler halinde belirtmiş olduğum ihtiyaçları karşılayacak bir veri tabanı kullanmamız gerekiyordu.
-
Esnek Veri Yapısı
İlişkisel veri tabanı yönetim sistemi ile işlerimizi yürüttüğümüz dönemdeki en büyük problemlerimizden biri, veri yapısının önceden belirlenmiş olması gereksiniminin önümüze çıkardığı zorluk idi. Dolandırıcılık/Suistimal vakalarının tespiti, yüzlerce farklı türdeki milyonlarca işlemin, ne zaman, nerede, nasıl yapıldığı gibi birçok bilgiyi bir araya getirerek karar verme yeteneğine sahip sistemler oluşturmayı gerektirmektedir. Her bir işlemin kendine has bir veri karakteristiği bulunmakta ve kendine özgü veri modelleri ile yönetilmektedir. Bu işlemlerin her biri potansiyel bir fraud vakası olabilmekte ve farklı data yapılarına sahip bu işlemlerin bir işlem havuzunda toplanabilmesi ve sonraki işlemlerde, kendisinden sonra gelecek işlemlerde de referans veri olarak kullanılabiliyor olması gerekmektedir.
İhtiyaç duyulduğunda herhangi bir verinin sadece tanımlamalar yapılarak sisteme alınabilmesi ve kullanılabilmesini sağlamamız gerekmekteydi.
-
Hızlı Geliştirme ve Aksiyon Alabilme Yeteneği
Dolandırıcıların ne zaman saldıracağı belirsiz olduğundan, aksiyonların anlık alınması ve sistemin bu durumlara hızlı adapte olması gerekiyor. İlişkisel model kullandığımız yapıda yeni bir verinin sağlanması için gerekli olan bilgilerin kullanılabilir hale getirilmesi, script'lerin oluşturulması ve veri tabanı üzerinde oluşturularak canlı ortamlara kadar geçilmesi için gerekli olan süreçler bu aksiyonları geciktirebiliyordu. Sisteme herhangi bir yeni bilgiyi dahil etmek istediğimizde bu değişikliği istediğimiz hızda yansıtamıyorduk çünkü alt ortamdan üst ortamlara doğru tablo değişikleri, kod değişiklikleri, stored procedure değişiklikleri vs. onay süreçlerinden geçirilerek yapılması gerekiyordu.
-
Merkezi Veri Yapısı
Diğer bir problem ise, ilişkisel veri yapısı ile merkezi bir veri modeli oluşturmaktaki zorluk olarak karşımıza çıkıyordu. İşlem setleri farklı farklı ve birbirinden alakasız veri yapılarına sahip olduğu için bunların hepsine ayrı ayrı tablolar yapıldığında merkezi bir noktaya verileri toplayamıyorduk. Var olan tüm verileri içeren bir tablo tasarımı dahi yapsak birçok boş değere sahip alanlardan oluşan tablo tasarımları oluşturmak gerekiyordu. Birçok null alandan oluşan tablo tasarımlarına gitmek verimsiz olmakta ve sürekli verinin aktığı tablolarda değişiklik yapılması da ayrı bir risk oluşturmaktaydı. Değerlendirdiğimiz diğer bir alternatif de key value şeklinde veri yapısı oluşturmak idi, fakat bu da efektif bir çözüm değil, işlem anında n adet insert operasyonu veya n adet datayı barındıran toplu insert'ler yapılmasını gerektiriyordu ki bu sistemlerde yazma performansı çok önemli ve yazmanın yoğun olarak aktığı tablolarda okuma hızları da etkileniyor.
Merkezi bir veri yapısının oluşturulamaması verilere farklı farklı noktalardan ulaşmayı gerektirdiği için işlem anında harcanan sürenin artmasına ve yeterince hızlı cevap verilememesine sebep oluyordu.
-
Artan İşlem Sayıları ve İşlem Çeşitliliğinde İhtiyaçları Karşılayabilme
Veri tabanında yönetilmesi gereken varlık/ilişki/kavram sayısının, işlem sayısının az olduğu, müşteri beklentilerinin bu kadar yüksek olmadığı zamanlarda bu durum ilişkisel veri tabanı alışkanlığının değiştirilmesini belki günümüzdeki kadar gerekli kılmıyordu. Ayrıca bu sistemlerin birtakım avantajlarından vazgeçmeyi gerektirecek kadar kritik bir noktaya henüz gelinmemişti. Bankacılık uygulamamız olan BOA'nın gelişimi ve şube, kanal ve ürün çeşitliliğinin artması ile birlikte bu kanallardan fraud tespit sistemine akması gereken işlem sayısının da artışı kaçınılmaz idi. Müşterilerimize kolaylık sağlayan ve anlık transferler yapmalarına olanak sağlayan FAST gibi yeni işlem türlerinin ortaya çıkması müşteri alışkanlıklarını ve beklentilerini de değiştirmeye başlarken, işlem anında cevap verme kabiliyetinin de arttırılabilmesi gibi gereksinimleri doğuruyordu (EFT ile yapılan diğer banka transferleri karşı bankaya geçmeden önce bir dakikaya varan bekleme süreleri olduğundan bu işlemlerin asenkron olarak kontrol edilebilmesi ve gerekli aksiyonların karşı bankaya transfer gerçekleşmeden önce alınabilmesi sağlanabiliyordu). Ayrıca işlem çeşitliği ve müşteriye ulaşılabilen kanal sayısı arttıkça bu durum dolandırıcılara da yeni yöntemler geliştirmeleri noktasında alan açıyordu. Geliştirilen bu yeni dolandırıcılık yöntemleri ve işlemler arasındaki ilişkilerin eskisine göre daha fazla sayıda olması sebebiyle, farklı kanallardaki işlem türlerinin birbiriyle ilişkisinin daha fazla dikkate alınmasını gerektirmeye başlamıştı. Örneğin dolandırıcının gerçekleştirmiş olduğu bir debit kart ile para çekme işleminin öncesindeki farklı bir işlem türü ile bağlantı olduğu durumlar olabiliyordu.
-
İzole Sistem İhtiyacı
İşlem sayısı arttıkça arka planda gerçekleştirdiği operasyonlar sistemde daha fazla yük oluşturuyordu. Alınan kararların izlenebilirliğini sağlayabilmek için her adımda elde edilen sonuçlar tablolara kaydediliyor, yoğun yazma ve okuma işlemlerinin sistemlere negatif yansıması olabiliyordu. Ana bankacılık işlemlerinin gerçekleştiği sunuculardan tamamen izole fakat yine "high available" çalışan bir sisteme ihtiyaç vardı. Yatayda ölçeklenebilir bir sistem olması da ilerideki ihtiyaçlara cevap verebilmesi açısından önemliydi.
Nihai Karar : NoSQL => MongoDB
Tüm bu ihtiyaçları değerlendirdğimizde NoSQL bir veritabanı ile ilerlememiz gerektiğine karar verdik. İşlemeye çalıştığımız veri yapısının daha çok içeriği birbirinden farklı dosyalar şeklinde olduğunu ve bu dosyalar içerisinden yüksek sorgulama kabiliyetli bir sisteme ihtiyaç duymaktaydık. Bu nedenle document-oriented bir yapının bizim için daha uygun olduğunu düşündük ve diğer faktörleri de göz önünde bulundurarak MongoDB’yi seçmeye karar verdik.
Seçimimizi etkileyen faktörler:
-
Dokuman temelli esnek veri yapısı ve sorgulama kabiliyeti
MongoDB’de tablo yerine collection kavramı kullanılıyor. Bir collection’daki her dokumanın gerektiğinde farklı içeriğe sahip olabilmesi, gerektiğinde şema kısıtlamalarıyla veri tipi kısıtlamalarının ayarlanabilmesi ve bu data yapısında gelişmiş sorgular çalıştırabilme yeteneği mevcut.
-
Popülerlik
Piyasada bilinen ve kullanılan bir sistem olması her zaman avantajlıdır. Tecrübesini paylaşacak bir çok geliştiriciden fikir alınabiliyor. Db-engines.com gibi veri tabanı popülerliğini ölçen sayfalara göre document based'larda aşağıdaki Tablo 2’deki gibi bir durum var. (Şubat 2025’teki durum)

Tablo 2 : DB-Engines Ranking'e Göre Document Based NoSQL Veri tabanı Popülerlik Skorları [3]
-
Community versiyonu ile geliştirme yaparak deneyimleyebilme
Free versiyonunun olması direk kullanım imkânı veriyor ve hızlıca indirip deneyimlemeye başlayabildik. Özellikle veritabanı yönetimi tarafında sağlanan daha üst seviye özellikler için Enterprise a geçmek ekstra bir çalışma gerektirmiyor. Lisans maliyetleri dışında aynı uygulamayı direk yönlendirerek geçiş yapabiliyoruz.
-
C# Driver'larının kullanımındaki kolaylık ve var olan altyapımız ile uyumlu çalışabilmesi
.Net ortamında yazılım geliştirme aşamalarında driver kullanımına rahatlıkla adapte olabildik.
-
Replicaset ve Sharding desteğinin olması
Replicaset mantığı ile birbirine otomatik olarak senkronize olan yedekli mimari ile kesinti olmadan iş yürütmek mümkün, gerektiğinde shard'lar oluşturarak veriyi farklı node'lara dağıtmak mümkün. Bir node’da çalışma yapılırken ve node kapatılırsa diğer node’lardan uygulama kesintisiz olarak hizmet verebiliyor.

-
Birden fazla türde engine desteği (gerekirse in-memory engine ile çalışabilme)
Verileri sadece memory'de tutabilen bir node konfigüre edilebiliyor. Veriniz memory'ye sığıyorsa isterseniz 2 in memory node ve 1 wired tiger node ile persistance'i destekleyebiliyorsunuz.
-
Enterprise versiyonu ile 7/25 support imkânı, OPS Manager ve LDAP Desteği
Community edition kullanılabiliyor fakat MongoDB'ye yeni iseniz ve büyük ölçekli bir sistem çalıştırıyorsanız support konusu her zaman önemli , bugüne kadar birçok farklı konuda hem uygulama tarafında hem de veri tabanı yönetimi tarafında support'a başvurduğumuz durum oldu. Özellikle yeni bir veritabanı sistemi ile çalışmaya başladığımız için bu destek bizim için çok önemliydi. Merkezi bir authentication yapısı olarak LDAP kullanmak istiyorsanız Enterprise versiyon ile gelen bu özellikten yararlanabiliyoruz. Büyük çaplı kuruluşlarda güvenlik ve merkezi kullanıcı yönetimi açısından önemli bir gereksinim olarak görülebilir. OPS Manager ise veritabanı yönetimi ekibinin işlerini kolaylaştırıyor.
-
Performans
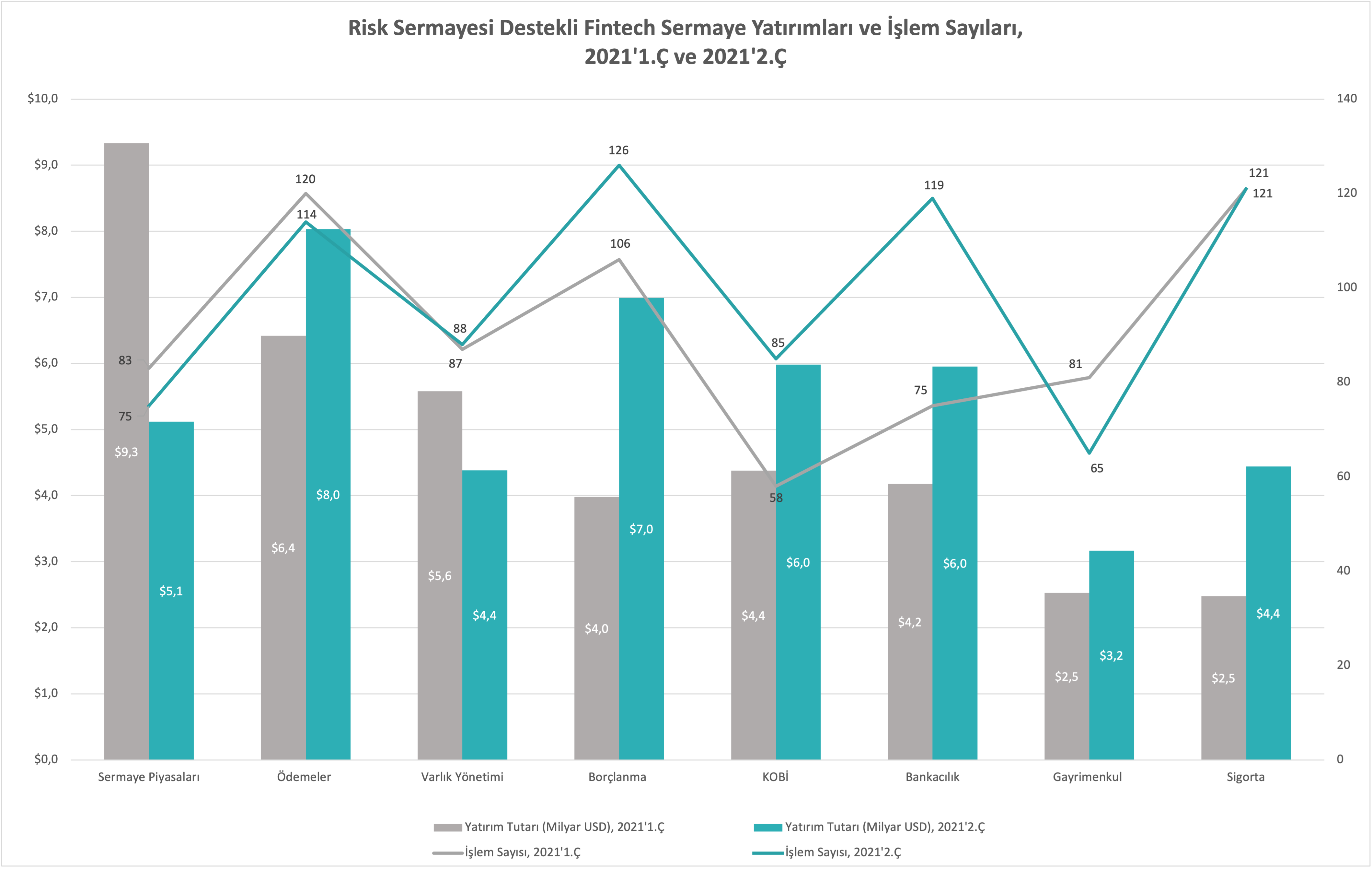
MongoDB’nin yazma, okuma ve silme performanslarının iyi olduğu biliniyor. Bu konuda karşılaştırma yapan makaleler de mevcut ve bazı birleştirilmiş operasyonlar dışında MongoDB'nin daha performanslı olduğu belirten araştırmalar var. [1]


Şekil 1.0 : MongoDB yazma performansları karşılaştırması [1]
-
Zamansal Index Yönetimi
TTL Index'ler ile ihtiyaç duyulmayan verilerin belirli bir süre sonra otomatik silinebilmesi ile veri boyutunu kontrol altına alabilme bizim uygulamamız için önemli bir özellik.
-
Agile Yazılım Geliştirme Süreçlerine Uygunluk
Hızlı yazılım geliştirme imkânı sağlıyor. Code first yaklaşım ile eski sisteme göre çok daha hızlı şekilde üretim yapabiliyoruz.
-
Driver’ların Otomatik Yönettiği İşlevler
Herhangi bir sunucunun kapanması veya bakım gibi işlemlerde driver'ın primary node'lara otomatik olarak geçiş sağlamasıyla node'larda kesintisiz şekilde işlemleri yürütebiliyoruz.
Zorlandığımız Konular
Bu süreçte yaşadığımız zorlukları aşağıdaki maddeler ile özetleyebiliriz:
-
Relational Tasarım Alışkanlığından Çıkma
İlişkisel veri tabanı alışkanlıkları sistem tasarımları esnasında düşünme şekillerini biçimlendirmektedir. Genellikle ilişkisel yapı terimleriyle düşünmeye alışkın olduğumuz için NoSQL kullanıyor olsak da uygulamanın tasarımını buna uygun yapmadığımız durumda beklenen kazanım elde edilemeyebilir.
MongoDB birbiriyle direk ilişkili ve birlikte erişilen verileri normalize ederek farklı tablolara yaymaktansa aynı document içerisinde tutmayı öneriyor. Böylece Atomicity’yi sağladığını belirtiyor. Bilgilerin iki farklı tabloya yayılıp foreign key'ler ile bağlanması ve join’lenerek erişilmesi gibi tasarım alışkanlıklarından kurtulmak gerekiyor.
Tabi her dokuman için bir max. boyut sınırı var o da 16 Mb.
-
MongoDB Sorgu Diline Alışma
İlk etapta bizi en çok zorlayan kısımlardan biri kompleks sorgular yazmaya çalıştığımızda bunun SQL'deki kadar kolay olmaması. Buna hala tam olarak alıştığımızı söyleyemiyorum. Çok esnek bir sorgu yapısı var fakat bir sorgu yazarken json formatında yazmaya alışmak gerekiyor.

Bazı tool'lar bu konuda SQL yazarak MongoDB Query'ye çevirme konusunda yardımcı oluyor fakat her yerde bu tool'lar kullanılamayabiliyor. Burada NoSQLBooster tool'undan da bahsetmemiz lazım. Bu alışma evresinde hem de sonrasında işimizi bayağı kolaylaştırdı. MongoDB Compass'a göre daha gelişmiş özellikler sunuyor.
-
MongoDB Compass’ın Yetersiz Kalması
MongoDB’nin kendini geliştirmesi gereken bir nokta olduğunu düşünüyorum. Compass ücretsiz olarak sunuluyor fakat bu tool veritabanı yönetiminde çok fazla kolaylık sağlamıyor, bunun yerine alternatif uygulamalarda birçok özellik sunulabiliyor. Biz NoSQLBooster ile devam etmeye karar verdik, çok daha kullanışlı bir tool olduğunu düşünüyoruz. Fakat belki alıştığımız ve yıllardır kullandığımız içindir hiçbiri SQL Server Management Studio’dan daha iyi diyemem.
-
Veritabanı Yönetimi ve Süreçlerin Oturması
Veritabanını sadece kullanmaya karar vermek ile iş bitmiyor, tecrübenin oluşması da zaman alıyor. Kurulum, veritabanı konfigürasyonu, bakım ve yedekleme operasyonlarının yürütülmesi için gerekli araç gereçlerinin yönetimine alışmak, erişim konfigürasyonu, hatta işletim sistemindeki bazı konfigürasyonlar dahi performansa etki edebiliyor, bu konularda MongoDB’den danışmanlık aldık fakat bilgi dağarcının oluşması ve hem yazılım hem veritabanı yönetimi ekiplerinin yeni sistemin davranışlarına adapte olabilmesi ve tecrübe kazanabilmesi için zaman gerekiyor.
-
Veriyi Farklı Bir Sistemdeki Verilerle Birleştirme İhtiyacı
Dataları collection'lara yazmak kolay fakat bunları okuyup Relational bir sistemdeki veriler ile birleştirip bir raporlama yapma gereksinim oluşursa zorluklar başlıyor. Veriyi export edecek tool'ları kullanarak çözülebilir fakat X DB'sine bir SP yazıp execute edip tempdB'e alıp joinlerim vs. gibi bir yöntem uygulanamıyor.
Nihai durumda performans ve veri tabanı işlem sayısı olarak daha optimize bir sistem, yanıt sürelerinde %50’ye yakın iyileşme, esnek ve kolay yönetilebilen arayüzler, merkezi bir veri modeli ve daha hızlı kod geliştirme gibi avantajlar elde ettik şeklinde özetleyebilirim.
Uygulama geliştirme açısından NoSQL Document Based bir sisteme geçiş ile ilgili tecrübelerimiz bu şekildeydi.
Farklı yazılarda görüşmek üzere.
Referanslar:
[5] İlişkisel Olmayan Veritabanları ve Türleri - GeeksforGeeks
“Bu içerik yalnızca mimari prensiplerimizin yüksek seviyede paylaşılması amacıyla hazırlanmıştır. Bankacılık güvenliğine ilişkin operasyonel süreçler, kural setleri, konfigürasyonlar ve uygulama detayları kapsam dışındadır.”